In this tutorial, you will learn how to create wordcloud/textcloud by demographic.
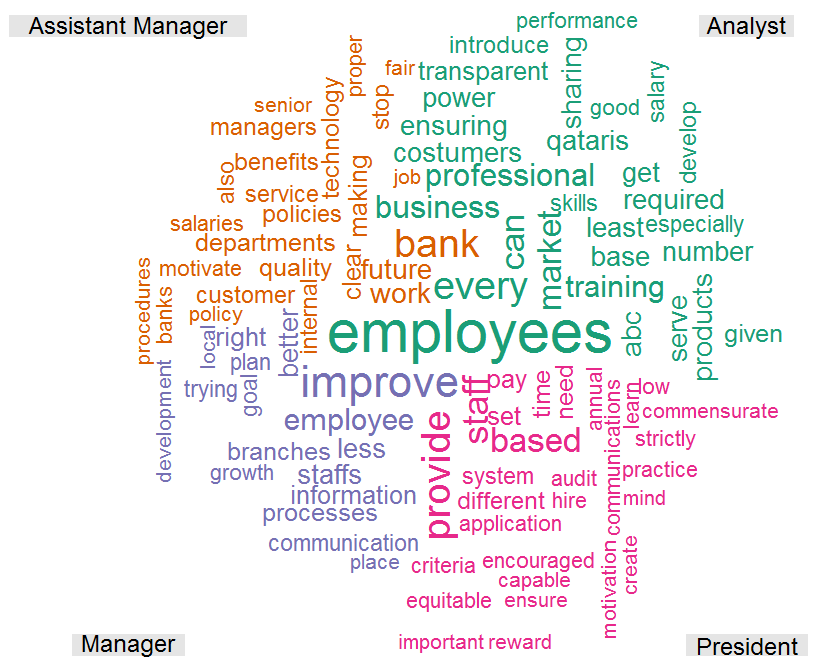
Suppose you wish to see the most frequently used keywords mentioned in the open-end comments written by analyst, assistant manager, manager, and president. In this case, the 'Comments' is the variable name where open-end comments are placed, and 'Designation' is the demographic.
You can download data file by clicking on this link - DataFile.
R Code For Comparative and Commonality WordCloud

You can download data file by clicking on this link - DataFile.
R Code For Comparative and Commonality WordCloud
library(tm)Output
library(wordcloud)
td = read.csv("text1.csv")
level1=paste(as.character(td$Comments[td$Designation==levels(td$Designation)[1]]), collapse=" ")
level2=paste(as.character(td$Comments[td$Designation==levels(td$Designation)[2]]), collapse=" ")
level3=paste(as.character(td$Comments[td$Designation==levels(td$Designation)[3]]), collapse=" ")
level4=paste(as.character(td$Comments[td$Designation==levels(td$Designation)[4]]), collapse=" ")
cloudfn<-function(text)
{ textCorpus<-Corpus(VectorSource(text))
textTDM<-TermDocumentMatrix(textCorpus,control=list(removePunctuation=TRUE,
stopwords=c(stopwords('english')),
removeNumbers=TRUE,tolower=TRUE))
# creating a data matrix
tdMatrix <- as.matrix(textTDM)
sortedMatrix<-sort(rowSums(tdMatrix),decreasing=TRUE)
cloudFrame<-data.frame(word=names(sortedMatrix),freq=sortedMatrix)
wcloudcategory<-wordcloud(cloudFrame$word,cloudFrame$freq,colors=brewer.pal(8,"Dark2"),
scale = c(5, 1), rot.per=.25, random.order=TRUE,min.freq=5)
print(wcloudcategory)
}
png(filename="level1.png",width=1200,height=1050)
cloudfn(level1)
dev.off()
png(filename="level2.png",width=1200,height=1050)
cloudfn(level2)
dev.off()
png(filename="level3.png",width=1200,height=1050)
cloudfn(level3)
dev.off()
png(filename="level4.png",width=1200,height=1050)
cloudfn(level4)
dev.off()
alltext=c(level1,level2,level3,level4)
tweetCorpus<-Corpus(VectorSource(alltext))
tweetTDM<-TermDocumentMatrix(tweetCorpus,control=list(removePunctuation=TRUE, stopwords=c(stopwords('english'),"amp"),
removeNumbers=TRUE,tolower=TRUE))
# creating a data matrix
tdMatrix <- as.matrix(tweetTDM)
#adding column names
colnames(tdMatrix)<-levels(td$Designation)
png(filename="comparative.png",width=1200,height=1050)
comparison.cloud(tdMatrix, random.order=FALSE,
colors = brewer.pal(8,"Dark2"),
title.size=2,scale=c(5,1),rot.per=.25,min.freq=10,max.words=100)
dev.off()
png(filename="commonality.png",width=1200,height=1050)
commonality.cloud(tdMatrix, random.order=FALSE,
colors = brewer.pal(8,"Dark2"),rot.per=.25,
scale=c(5,1))
dev.off()

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Hi Deepanshu,
ReplyDeleteThanks for sharing this valuable code.
I am trying to use this code, but word cloud is not getting generated, I am receiving below warning as well when code was executed,
Can you please let me know the why charts are not getting generated?
Ignore above query the I able to see word cloud, thanks a lot for sharing a tip
Delete