This tutorial explains how to identify the first and last observations within a group using the first. and last. variables in SAS. It is a common data cleaning step to remove duplicates or store unique values. This method is an alternative to SQL window functions such as rank over() that generate serial numbers among a group of rows.
FIRST.VARIABLE assigns the value of 1 for the first observation in a BY group and the value of 0 for all other observations in the BY group.
LAST.VARIABLE assigns the value of 1 for the last observation in a BY group and the value of 0 for all other observations in the BY group.
Note : Data set must be sorted BY group before applying FIRST. and LAST. Variables.
Suppose you have a dataset consisting 3 variables and 12 observations. The variables are ID, Name and Score. The variable ID is a grouping variable and it contains duplicates.
The following program creates a sample dataset in SAS to explain examples in this tutorial.
data readin; input ID Name $ Score; cards; 1 David 45 1 David 74 2 Sam 45 2 Ram 54 3 Bane 87 3 Mary 92 3 Bane 87 4 Dane 23 5 Jenny 87 5 Ken 87 6 Simran 63 8 Priya 72 ; run;
Use PROC SORT to sort the data set by ID. It is required to sort the data before using first. and last. variables.
PROC SORT DATA = READIN; BY ID; RUN; DATA READIN1; SET READIN; BY ID; First_ID= First.ID; Last_ID= Last.ID; RUN;
Note : FIRST. and LAST. variables are temporary variables. That means they are not visible in the newly created data set. To make them visible, we need to create two new variables. In the program above, I have created First_ID and Last_ID variables.
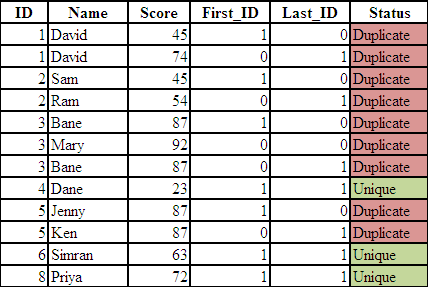
- FIRST.variable = 1 when an observation is the first observation in each group values of variable ID.
- FIRST.variable = 0 when an observation is not the first observation in each group values of variable ID.
- LAST.variable = 1 when an observation is the last observation in each group values of variable ID.
- LAST.variable = 0 when an observation is not the last observation in each group values of variable ID.
When FIRST.variable = 1 and LAST.VARIABLE = 1, it means there is only a single value in the group. (See ID = 4 in the above data for reference)
Suppose you need to select only the first observation among a group of observations. It is very easy to do it with IF statement. The IF statement subsets data when IF is not used in conjunction with THEN or ELSE statements.
PROC SORT DATA = READIN; BY ID; RUN;
DATA READIN1; SET READIN; BY ID; IF FIRST.ID; PROC PRINT; RUN;
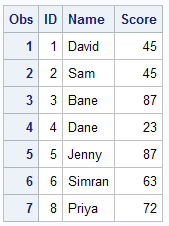
Note : It returns first observation among values of a group (total 7 observations).
Suppose you are asked to include only last observation from a group. Like the previous example, we can use last. variable to subset data.
PROC SORT DATA = READIN; BY ID; RUN;
DATA READIN1; SET READIN; BY ID; IF LAST.ID; PROC PRINT; RUN;
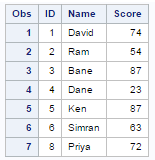
No. WHERE statement cannot be used with First. and Last. Variables. It is because WHERE statement requires variables already be created in the dataset before processing.
Suppose you need to create serial numbers among a group of observations. See the snapshot below -
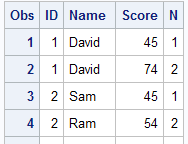
Data temp; set readin; by ID; if first.id then N = 1; else N +1; proc print; run;
In the above program, we are setting N=1 when it is the first value of a group i.e. ID. Otherwise adding 1 to N. The N+1 implies N = N + 1 in BY group processing. When there is a second observation in a group, N+1 adds 1 to N=1 so N becomes 2. It further increments by 1 when there is third observation in the group and so on.
Suppose you need to calculate running cumulative score by variable ID.
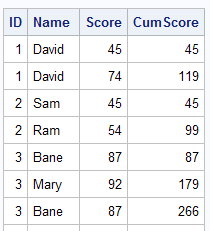
Data temp; set readin; by ID; if first.id then CumScore = Score; else CumScore + Score; proc print; run;
In the above program, we are setting Cumscore = Score when it is the first value of a group i.e. ID. Otherwise adding Score to Cumscore. The Cumscore + Score implies CumScore = CumScore + Score in BY group processing.
data unique duplicates; set readin; by id; if first.id = 1 and last.id = 1 then output unique; else output duplicates; run;
- The DATA statement creates two temporary SAS data sets: DUPLICATES AND UNIQUE.
- The SET statement reads observations from data set READIN.
- The BY statement tells SAS to process observations by ID. Variables FIRST.ID and LAST.ID are created.
- If the first and last observation have the same value, it implies it is a unique value; otherwise, the value is a duplicate.
1. Identify and select only records having maximum Score among a group of observations of variable ID
2. Select unique observations plus second observation from duplicate observations of variable ID
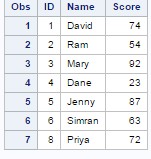
First we need to build a logic how we can select records having max score within variable ID. We can do it via PROC SORT. In this case, we need to sort data by 2 variables - first sorting on variable ID and then next sorting on Score by descending order. The DESCENDING keyword is used in PROC SORT to arrange data from largest to smallest. Sorting on descending order is used to place the max value at first observation in each group of ID.
proc sort data= readin; by ID descending score; run; data readin1; set readin; by ID; if first.id; run;
After sorting, we retain records having maximum value by using FIRST. and IF statement. The IF FIRST.ID keeps the first record among a group of values of variable ID. The output is shown in the image below.
Solve second example yourself and post your answer in the comment box below. Make sure it should be solved in one data step code. Hint : BOTH FIRST. and LAST. variables would be used.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
nice explaination
ReplyDeletegood explanation and good examples
ReplyDeletedata test8;
ReplyDeleteset readin;
by ID;
if first.ID =1 and last.ID = 1 then output test8;
else if mod(_n_,2) = 0 then output test8;
run;
proc print; run;
data uniq_or_Dup2;
Deleteset readlin;
if (first.Id=1 and last.id=1) or (lag1(first.id)=1 and first.id=0) then output uniq_or_Dup2;
proc print
run;
proc sort data =readin out=test;
Deleteby id Score;
run;
data test1 ;
set test;
by id ;
if first.id then N=1;
else N+1;
if first.ID=1 and last.id=1 or N=2;
drop N;
run;
data test1;
Deleteset readin;
by id;
if last.id=1 ;
run;
proc sort data=data;
ReplyDeleteby ID;
run;
data data1;
set data;
by ID;
if first.ID=1 then serial=1;
else serial+1;
run;
data data2;
set data1;
by id;
if first.ID=1 and last.ID=1 or serial=2;
run;
good one..thanks
Deleteif we have four duplicates how can we get second one ?
ReplyDeleteGood one
Deletedata test8;
ReplyDeleteset readin;
by ID;
if first.ID =1 and last.ID = 1 then output test8;
if first.id and last.id=0 then N=1;
else N+1;
if N=2 then output test8;
drop N;
run;
data nk;
ReplyDeleteset readin;
by id;
if first.id then N=1;
else N+1;
if N=2 then output;
if first.id and last.id then output;
drop N;
proc print;
run;
data new2;
ReplyDeleteset readin1;
retain cnt;
if first_id=1 then cnt=1;
else cnt+1;
if cnt le 2;
run;
this is the best logic ,i guess. you forgot to add by statement. i am just starter and took time to findout that ...
Deleterajeshmanepalli987@gmail.com,if you are comfortable and ready to help, I have some doubts adn will drop a mail to you.If you are intersted ,no problem. thanks.
Deletedata ad;
ReplyDeleteset abcd_s;
by x;
if first.x and last.x then output;
if first.x then n=1;
else n+1;
if n=2 then output;
drop n;
run;
Data Readin2;
ReplyDeleteset readin;
by id;
if first.id then n =1;
Else n+1;
if first.id = 1 and last.id= 1 or n = 2;
drop n
Run;
Its very helpful, I have come across many questions in my interviews
ReplyDeletedata gaurav;
ReplyDeleteset readin;
by id;
if first.id then N=1;
else N+1;
if (first.id=1 and last.id=1) then output;/* unique observation*/
if N=2 then output;/* second observation from duplicate*/
run;
proc print;
run;
If we have 4 or more than 4 duplicate ids then what would be the logic to find out 2nd observation?
ReplyDeleteThanks!
if i want to calculate average per person then how to calculate??
ReplyDeleteproc sort data= readin;
Deleteby ID Score;
run;
data temp;
set readin;
by ID;
if first.ID then
do;
N=1;
cumScore = Score;
avgScore = Score;
end;
else
do;
N+1;
cumScore + Score;
avgScore = cumScore/N;
end;
if last.ID = 1;
run;
data avg;
Deleteset score;
by ID;
IF first.ID then COUNT=1 ELSE COUNT = COUNT+1;
IF first.ID then SUM = MARKS ELSE SUM = SUM+MARKS;
IF LAST.ID then AVG = SUM/COUNT;
RUN;
Doesn't generating serial numbers as well as cumulative rank require the newly created variables - N and Cum Score to be retained. Else, SAS will not be able to store their values jumping from one obs to the next ?
ReplyDeleteBelow code is working for case study 2. Let me know if anybody still facing any problem in solving or understanding this question.
ReplyDeleteproc sort data=READIN;
BY ID Descending score;
run;
DATA READIN2;
SET READIN;
BY ID ;
First_ID= First.ID;
Last_ID= Last.ID;
IF first.id then N=1;
ELSE N+1;
if (FIRST_ID=1 and LAST_ID=1) or N=2 then output READIN2 ;
drop First_ID Last_ID N;
proc print;
run;
Gd one.
DeleteHow can we use ELSE N+1 in data step with using retain? Data step works obs by obs din't N loses its previous value in every next iteration?
ReplyDeleteI know, I am missing something, but what?
Retain can be used in two ways:
Delete1. Implicitly : We can use retain implicitly by using +1 notation. If we use retain implicitly then we don't need to write retain statement. just like above code.
Another example :
data a;
set xyz;
by id;
if first.id then x=1;
else x+1 : /which means x=x+1 but we are using retain implicitly so no need to mention x= here;
run;
2. Explicitly
Using the same example where we are using retain explicitly so need to mention retain statement.
data a;
set xyz;
by id;
retain x;
if first.id then x=1;
else x=x+1 : /here we are using x= so need to mention retain statement;
run;
ReplyDeleteproc sort data=test;
by id score;
run;
data readin;
set test;
by id score;
first_var=first.id;
last_var=last.id;
if (first_var=1 and last_var=1) or last_var=1;
run;
proc sort data=test;
ReplyDeleteby id;
run;
data readin;
set test;
by id;
if (first.id=1 and last.id=1) then output unique;
if (last.id=1) then output second_dup;
run
proc print;
run;
"if (last.id=1) then output second_dup;" will give unique records as well.
Deletemoreover if we have more than 2 records for for any ID then it will give last record for that and not the second record.
So this will work only for those IDs which are having exactly 2 records only.
It will be better if you can assign serial number by grouping on ID basis and then select value for that serial no=2 for 2nd observation.
Please let me know if you are having any confusion at any point.
data readin1;
ReplyDeleteset readin;
by id;
if first.id=1 and last.id=1 then serial=1;
else serial+1 ;
run;
data readin2;
set readin1;
where serial=1 or serial=2;
run;
data aaa;
ReplyDeleteset readin;
by id;
if first.id then n=1;
else n+1;
if not (first.id and last.id) and n<=2;
run;
data unique (drop =N) second (drop =N);
ReplyDeleteset readin;
by id;
retain N;
if first.id =1 and last.id =1 then output unique ;
if first.id then N= 1;
else N= N+1;
if N =2 then output second;
run;
PROC SORT DATA=READIN;
ReplyDeleteBY ID;
RUN;
DATA TEMP;
SET READIN;
BY ID;
IF FIRST.ID=1 AND LAST.ID=1 THEN OUTPUT TEMP;
ELSE IF MOD(_N_,2)=0 THEN OUTPUT TEMP;
RUN;
PROC PRINT;
RUN;
Hi All, With refer to below dataset, Can anyone please assist me I want to have all those Empid's who have done more then 5 Transactions
ReplyDeletedata temp;
input EMPID Expenses;
CARDS;
101 200
102 300
103 200
104 500
105 600
101 450
102 600
101 400
101 200
101 700
102 600
101 800
101 500
102 900
101 500
102 600
102 800
102 600
102 900
102 700
102 600
102 600
103 800
;
someone please try to give solution for this query.
Deleteproc sort data =temp;
Deleteby EMPID;
data test;
set temp;
by EMPID ;
if first.EMPID=1 then N=1;
else N+1;
run;
Data Final(Keep=EMPID);
set test;
where N>=5;
run;
data temp;
Deleteinput EMPID Expenses;
CARDS;
101 200
102 300
103 200
104 500
105 600
101 450
102 600
101 400
101 200
101 700
102 600
101 800
101 500
102 900
101 500
102 600
102 800
102 600
102 900
102 700
102 600
102 600
103 800
;run;
proc sort data=temp out=ani;by EMPID;run;
data akshay;
set ani;
by EMPID;
if first.EMPID=1 then Transactions=1;
else Transactions+1;
if Transactions gt 5;
if last.EMPID;
run;
proc sort data = temp;
Deleteby EMPID;
run;
data outdata;
set temp;
if first.empid= 1 then query = 1 ;
else query +1 ;
if last.empid ;
run;
data final ;
set outdata ;
where query gt 5 ;
run;
Anyone please help me out with the above scenario its really urgent.Thanks in advance
ReplyDeletehow to give the serial number to the dates by patients wise ....
ReplyDeletePt Date want in Days or want as serial
43 10/9/2018 DAY 1 1
43 10/10/2018 DAY 2 2
43 10/11/2018 DAY 3 3
43 10/12/2018 DAY 4 4
43 10/13/2018 DAY 5 5
43 10/15/2018 DAY 7 7
44 10/9/2018 DAY 1 1
44 10/11/2018 DAY 3 3
45 10/9/2018 DAY 1 1
45 10/10/2018 DAY 2 2
45 10/12/2018 DAY 4 4
given like this ,,...
ReplyDeletePt Date
43 10/9/2018
43 10/10/2018
43 10/11/2018
43 10/12/2018
43 10/13/2018
43 10/15/2018
44 10/9/2018
44 10/11/2018
45 10/9/2018
45 10/10/2018
45 10/12/2018
and convert as the
ReplyDeletePt want in Days or want as serial
43 DAY 1 1
43 DAY 2 2
43 DAY 3 3
43 DAY 4 4
43 DAY 5 5
43 DAY 7 7
44 DAY 1 1
44 DAY 3 3
45 DAY 1 1
45 DAY 2 2
45 DAY 4 4
in SAS
data akshay;
Deleteinput
id date:anydtdte10. day$ &;
format date:mmddyy8.;
cards;
43 10/09/2018 DAY 1
43 10/10/2018 DAY 2
43 10/11/2018 DAY 3
43 10/12/2018 DAY 4
43 10/13/2018 DAY 5
43 10/15/2018 DAY 7
44 10/9/2018 DAY 1
44 10/11/2018 DAY 3
45 10/9/2018 DAY 1
45 10/10/2018 DAY 2
45 10/12/2018 DAY 4
;run;
proc sort data=akshay;by id;run;
data final;
set akshay;
by id;
if first.id=1 then serial_no=1;
else serial_no+1;
run;
proc sort data= readin;
ReplyDeleteby id;
run;
data unique duplicate;
set readin;
if first.id=1 and last.id=1 then output unique;
else output duplicate;
run;
proc sort data= duplicate;
by id;
run;
data duplicate;
set duplicate;
by id;
if first.id;
run;
If we want to select every third observations from a group then how we can get this. Note: we can't sort this because we don't want every third after sorting we want the third one from every group as it is.
ReplyDeletePROC SORT DATA=READIN OUT=READ1;
ReplyDeleteBY ID ; RUN;
DATA READ2;
SET READ1;
BY ID;
IF (FIRST.ID=0 AND LAST.ID=1) OR (FIRST.ID=1 AND LAST.ID=1);
RUN;
PROC SORT DATA=READIN;
ReplyDeleteBY ID;
RUN;
/*DATA UNIQUE SECOBS;*/
DATA OBS;
SET READIN;
BY ID DESCENDING SCORE;
/*IF FIRST.ID=1 AND LAST.ID=1 THEN OUTPUT UNIQUE;*/
IF FIRST.ID=1 AND LAST.ID=1 THEN OUTPUT OBS;
/*ELSE IF FIRST.ID=0 AND LAST.ID=1 THEN OUTPUT SECOBS;*/
ELSE IF FIRST.ID=0 AND LAST.ID=1 THEN OUTPUT OBS;
PROC PRINT;
RUN;
PROC PRINT DATA=UNIQUE;
RUN;
PROC PRINT DATA=SECOBS;
RUN;
Hi need some help
ReplyDeleteid var1 var2
1 20 30
1 40 50
1 30 55
2 22 45
2 37 49
3 79 36
4 36 49
4 68 78
I need to find the mean of var1 and var2 individually for the same ID
and fix it to the same ID variable
for example for ID 1 var1=mean(20,40,30) var2=mean(30,50,55)
and should show
ID Var1 Var2
1 30 45
2 29.5 47
.
.
.
Thank you
data akshay;
Deleteinput
id var1 var2;
cards;
1 20 30
1 40 50
1 30 55
2 22 45
2 37 49
3 79 36
4 36 49
4 68 78
;
run;
proc sort data=akshay;by id;run;
proc means data=akshay mean;
by id;
var var1 var2;
output out=semifinal
mean(var1)= var1
mean(var2)=var2; ;
run;
data final;
set semifinal;
drop _TYPE_ _FREQ_;
run;
data temp;
Deleteinput id var1 var2;
cards;
1 20 30
1 40 50
1 30 55
2 22 45
2 37 49
3 79 36
4 36 49
4 68 78
;
run;
proc means data=temp mean ;
class id;
output out=temp1 (where=(_type_>0 and _stat_="MEAN")) ;
run;
data temp2;
set temp1(keep= id var1 var2);
run;
Data t;
ReplyDeleteInput x$ y;
A 5
B 3
C 4
A 6
B 9
C 3
;
Run;
How to get out put
Sum of
A=
B=
C=
proc means data=t sum;
Deleteclass x;
run;
DeleteData t;
Input x$ y;
cards;
A 5
B 3
C 4
A 6
B 9
C 3
;
Run;
proc sort data = t ;
by x;
run;
data final ;
set t;
by x;
if first.x then sum= y ;
else sum +y ;
if last.x;
keep x sum ;
run;
Hi All, With refer to below dataset, Can anyone please assist me I want to have all those Empid's who have done more then 5 Transactions
ReplyDeletedata temp;
input EMPID Expenses;
CARDS;
101 200
102 300
103 200
104 500
105 600
101 450
102 600
101 400
101 200
101 700
102 600
101 800
101 500
102 900
101 500
102 600
102 800
102 600
102 900
102 700
102 600
102 600
103 800
;
PROC SORT DATA=temp;
DeleteBY EMPID;
RUN;
DATA TEST;
SET TEMP;
BY EMPID;
IF FIRST.EMPID THEN COUNT=0;
COUNT+1;
IF COUNT GT 5;
IF LAST.EMPID;
RUN;
SOLUTION OF 2ND QUERY:
ReplyDeletePROC SORT DATA =READIN;
BY ID;
RUN;
DATA T1;
SET READIN;
BY ID;
IF FIRST.ID = 1 AND LAST.ID =1 THEN STATUS='UNIQUE';
IF FIRST.ID =0 AND LAST.ID =1 THEN STATUS= SCORE;
RUN;
hi,
Deletewhat if happens if first.id=1 and last.id=0, so we can write like this way , i say we could also write like this,
if first.id=0 and last.id=1 or first.id=1 and last.id=0 then status='SCORE';
CODE::
data T1;
set readin;
by id;
unique=first.id;
duplicate=last.id;
if first.id=0 and last.id=1 or first.id=1 and last.id=0 then status='SCORE';
if first.id=1 and last.id=1 then status='unique';
run;
proc print data=T1;
run;
proc sort data =readin out=test;
ReplyDeleteby id Score;
run;
data test1 ;
set test;
by id ;
if first.id then N=1;
else N+1;
if first.ID=1 and last.id=1 or N=2;
drop N;
run;
data record;
ReplyDeleteinput id name $ score;
cards;
1 david 45
1 david 74
2 sam 45
2 ram 54
3 bane 87
3 mary 92
3 Bane 87
4 Dane 23
5 Jenny 87
5 Ken 87
6 Simran 63
8 Priya 72
;
run;
/*Select unique observations plus second
observation from duplicate observations of
variable ID */
proc sort data=record;
by ID;
run;
data data2 data3;
set record;
by id;
if (first.ID=1 or last.ID=1) then output data2;
else output data3;
run;
proc sort data=readin out=r_sorted;
ReplyDeleteby id descending score;
run;
data unique_sec;
set r_sorted;
by id descending score;
if first.id then n=1;
else n+1;
if first.id and last.id or n=2;
drop n;
run;
data uniques duplicates;
ReplyDeleteset readin;
by id;
if first.id = 1 and last.id=1 then output uniques;
if first.id then n = 1;
else n+1;
if n = 2 then output duplicates;
run;
Hello all,
ReplyDeleteData ADaM;
Input visit$ visitnum paramcd$ aval;
cards;
v3 3 Hb 9
v4 4 HR 67
sc1 1 Hb 6
sc2 2 Hb 8
v2 2 HR 78
v3 3 HR 85
sr1 0 HR 70
sr2 1 HR 69
;
run;
proc sort data=ADaM out=ADaM1;
by paramcd visitnum;
run;
here i need to find the baseline values, baseline is avail first observation+second observation/2 is the baseline for every paramcd,
Example: if paramcd Aval baseline
HR 10
HR 20 15 (10+20/2),
even i have somany HR paramcds it should be baseline 15 for HR,
HB 20
HB 30 25
even i have somany HB paramcds it should be baseline 25 for HR,
Please can any one help on it.
how to create that ID variable with first. and last.?
ReplyDelete