This tutorial explains how to ignore duplicates while specifying conditions / criteria in SQL queries. You must have used DISTINCT keyword to remove duplicates. It is frequently used with COUNT function to calculate the number of unique cases.
Suppose you have three variables, say, 'id', 'x' and 'y'. You need to calculate number of distinct "y" values when x is less than 30. See the snapshot of data below -
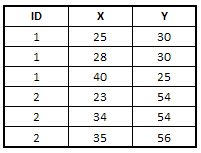
data temp; input id x y ; cards; 1 25 30 1 28 30 1 40 25 2 23 54 2 34 54 2 35 56 ; run;
proc sql; select count(distinct y) as unique_y, count(distinct case when x < 30 then y else . end) as unique_criteria from temp; quit;
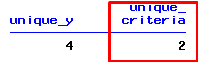
- The above program computes number of distinct values in variable 'y' when values of variable "x" is less than 30.
- The keyword DISTINCT is used to remove or ignore duplicate records.
- In the dataset, there are in total 3 cases in variable 'y' when x < 30. Whereas distinct number of cases in variable 'y' is equal to 2.
Suppose you are asked to group values by ID and then calculate sum of distinct values of y when x < 30. If condition is not met, then sum of all values of y.
proc sql; select id, sum(distinct y) as sum_unique, coalesce(sum(distinct case when x < 30 then y end),0) + coalesce(sum(case when x >= 30 then y end),0) as sum_unique_criteria from temp group by 1; quit;

- Since the DISTINCT keyword works on a complete record, we need to write conditions "x <30" and "x>=30" separately in CASE WHEN.
- The COALESCE function tells SAS to replace missing values with 0 and then sum the returned values of both the conditions. If we don't use COALESCE, it would return missing when any of the two values which we want to add contains missing/null.
Suppose you are asked to group data by variable 'ID' and then calculate maximum value of variable 'Y' when x is less than 30. Otherwise take all the values. At last, sum the returned values of both the conditions.

data temp; input id x y ; cards; 1 25 30 1 28 27 1 40 25 2 23 54 2 29 55 2 34 56 ; run; proc sql; select id, coalesce(max(case when x < 30 then y end),0) + coalesce(sum(case when x >= 30 then y end),0) as sum_unique_criteria from temp group by 1; quit;
Suppose you need to pick the maximum value in variable Y when duplicates in variable "X" and then group data by variable "ID" and compute number of cases where Y=1.
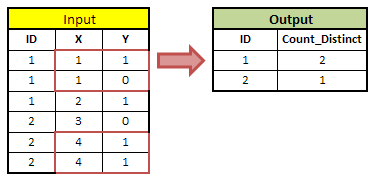
data temp; input id x y ; cards; 1 1 1 1 1 0 1 2 1 2 3 0 2 4 1 2 4 1 ; run; proc sql; select a.id, count(distinct case when y > 0 then max_y else . end) as count_distinct from temp a left join (select x, max(ranuni(123) * y) as max_y from temp group by 1) b on a.x = b.x group by 1; quit;
- When X = 1, it picks the maximum value of variable Y i.e. 1 and sets Y =1. Then it groups data by variable "ID", it checks the number of cases in which Y is equal to one after removing duplicates in X=1 cases. So it returns 2.
- The RANUNI() function is used to generate random numbers between 0 and 1 without replacement.The number 123 that is enclosed in the ranuni function is called seed which produces the same random numbers when it is run next time.
- In this case, the RANUNI() function makes Y as unique identifier so that we can later count these unique cases.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Hi - I don't understand the last SQL query - can you further explain?
ReplyDeleteSuperb article
ReplyDeleteI have looked all over for the process to just "ignore" duplicate rows in Spotfire. Everything I find it about writing long expressions and inseting new columns to remove duplicate rows. this is the simple and easy button solution Fantastic!
ReplyDeletedata ss;
ReplyDeleteinput id;
datalines;
1
2
3
4
5
-1
-2
-3
-4
-5
;
run;
i want sum of positive value in one variable and negative value in another variable
data sum1 minus1;
Deleteset ss;
if id >=0 then output sum1;
else output minus1;
run;
data want;
ReplyDeleteset ss;
retain positive negative 0;
if id>0 then positive+a;
else negative+a;
run;
can we use firstobs and obs concept
DeleteGreat content overall. Thanks to the Author.
ReplyDeleteOne request, could you please add details about PROC REPORT and PROC TEMPLATE here?