It is one of the most common data manipulation problem to find records that exist only in table 1 but not in table 2. This post includes four methods with PROC SQL and one method with data step to solve it.
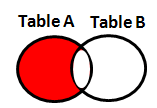
This problem statement is also called 'If a and not b' in SAS. It means pull records that exist only in Table A but not in Table B (Exclude the common records of both the tables). See the Venn Diagram below -
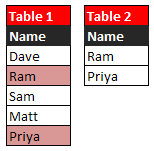
The following programs create two data sets in SAS which are used to demonstrate methods to solve this problem.
data dataset1; input name $; cards; Dave Ram Sam Matt Priya ; run;
data dataset2; input name$; cards; Ram Priya ; run;
If you look at the tables below, we are looking to fetch all the records from table1 except 'Ram' and 'Priya' as these two names are in table2.
In SAS, there are multiple ways to solve this problem. The methods are listed below -
The simplest method is to write a subquery and use NOT IN operator, It tells system not to include records from dataset 2.
proc sql; select * from dataset1 where name not in (select name from dataset2); quit;
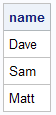
The output is shown in the image below -
In PROC SQL, the EXCEPT clause is used to combine the result of two SELECT statements and returns rows from the first SELECT statement that are not returned by the second SELECT statement.
proc sql; select * from dataset1 except select * from dataset2; quit;
The SELECT statements before and after the EXCEPT clause must have the same number of columns. The variable types of both the tables must be same.
In this method, we are performing left join and telling SAS to include only rows from table 1 that do not exist in table 2.
proc sql; select a.name from dataset1 a left join dataset2 b on a.name = b.name where b.name is null; quit;
In the first step, it reads common column from the both the tables - a.name and b.name. At the second step, these columns are matched and then the b.name row will be set NULL or MISSING if a name exists in table A but not in table B. At the next step, WHERE statement with 'b,name is null' tells SAS to keep only records from table A.
NOT EXISTS subquery writes the observation to the merged dataset only when there is no matching rows of a.name in dataset2. This process is repeated for each rows of variable name.
proc sql; select a.name from dataset1 a where not exists (select name from dataset2 b where a.name = b.name); quit;
Step 1 - At the background, it performs left join of the tables -
proc sql; create table step1 as select a.* from dataset1 a left join dataset2 b on a.name = b.name; quit;
Step 2 - At the next step, it checks common records by applying INNER JOIN
proc sql; create table step2 as select a.name from dataset1 a, dataset2 b where a.name = b.name; quit;
Step 3 - At the last step, it excludes common records.
proc sql; select * from step1 where name not in (select distinct name from step2) ; quit;
In SAS Data Step, it is required to sort tables by the common variable before merging them. Sorting can be done with PROC SORT.
proc sort data = dataset1; by name; run; proc sort data = dataset2; by name; run;
Data finaldata; merge dataset1 (in=a) dataset2(in=b); by name; if a and not b; run;
The MERGE Statement joins the datasets dataset1 and dataset2 by the variable name.
To answer this question, let's create two larger datasets (tables) and compare the 4 methods as explained above.
Table1 - Dataset Name : Temp, Observations - 1 Million, Number of Variables - 1
Table2 - Dataset Name : Temp2, Observations - 10K, Number of Variables - 1
data temp; length x $15.; do i = 1 to 1000000; x = "AA"||strip(i); output; end; drop i; run;
data temp2; length x $15.; do i = 1 to 10000; x = "AA"||strip(i); output; end; drop i; run;
SAS Dataset MERGE (Including prior sorting) took least time (1.3 seconds) to complete this operation, followed by NOT IN operator in subquery which took 1.4 seconds and then followed by LEFT JOIN with WHERE NULL clause (1.9 seconds). The NOT EXISTS took maximum time.
Important Note - In many popular forums, it is generally advised to use NOT EXISTS rather than NOT IN. This advise is generally taken out of context. Modern softwares use SQL optimizer to process any SQL query. Some softwares may consider both the queries as same in terms of execution so there would not be a noticeable difference in their CPU timings. Some may be in favor of NOT EXISTS. SAS seems to be in favor of NOT IN operator as it does not require tables to be merged.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
proc sql;
ReplyDeleteselect * from dataset1
except
select * from dataset2;
quit;
WOW :O
Deletewe can also use the minus operator..
ReplyDeleteWhat if we have 2 variables, name and date?
ReplyDelete