Predictive modeling knowledge is one of the most sought-after skill today. It is in demand these days. It is being used in almost every domain ranging from finance, retail to manufacturing. It is being looked as a method of solving complex business problems. It helps to grow businesses e.g. predictive acquisition model, optimization engine to solve network problem etc.
It is not easy to get into these roles as it requires technical understanding of various statistical techniques and machine learning algorithms with tools like SAS/R/Python. Hence, it is important to prepare well before going for interview. To help you in interview preparation, I’ve jot down most frequently asked interview questions on logistic regression, linear regression and predictive modeling concepts. In general, an analytics interview process includes multiple rounds of discussion. Possible rounds are as follows -
It is not easy to get into these roles as it requires technical understanding of various statistical techniques and machine learning algorithms with tools like SAS/R/Python. Hence, it is important to prepare well before going for interview. To help you in interview preparation, I’ve jot down most frequently asked interview questions on logistic regression, linear regression and predictive modeling concepts. In general, an analytics interview process includes multiple rounds of discussion. Possible rounds are as follows -
- Technical Round on Statistical Techniques and Machine Learning Concepts
- Technical Round on Programming Languages such as SAS/R/Python/SQL
- Managerial Round on Business/Domain Knowledge
During these multiple rounds of interviews, they also check your communication skill and logical/ problem solving skill.
 |
| Predictive Modeling Interview Questions |
Let's start with a list of some basic and tricky predictive modeling interview questions with answers.
1. What are the essential steps in a predictive modeling project?
It consists of the following steps -
- Establish business objective of a predictive model
- Pull Historical Data - Internal and External
- Select Observation and Performance Window
- Create newly derived variables
- Split Data into Training, Validation and Test Samples
- Clean Data - Treatment of Missing Values and Outliers
- Variable Reduction / Selection
- Variable Transformation
- Develop Model
- Validate Model
- Check Model Performance
- Deploy Model
- Monitor Model
2. What are the applications of predictive modeling?
Predictive modeling is mostly used in the following areas -
- Acquisition - Cross Sell / Up Sell
- Retention - Predictive Attrition Model
- Customer Lifetime Value Model
- Next Best Offer
- Market Mix Model
- Pricing Model
- Campaign Response Model
- Probability of Customers defaulting on loan
- Segment customers based on their homogenous attributes
- Demand Forecasting
- Usage Simulation
- Underwriting
- Optimization - Optimize Network
3. Explain the problem statement of your project. What are the financial impacts of it?
Cover the objective or main goal of your predictive model. Compare monetary benefits of the predictive model vs. No-model. Also highlights the non-monetary benefits (if any).
4. Define observation and performance window?
Tutorial : Observation and Performance Window
5. Difference between Linear and Logistic Regression?
Two main difference are as follows -
- Linear regression requires the dependent variable to be continuous i.e. numeric values (no categories or groups). While Binary logistic regression requires the dependent variable to be binary - two categories only (0/1). Multinomial or ordinary logistic regression can have dependent variable with more than two categories.
- Linear regression is based on least square estimation which says regression coefficients should be chosen in such a way that it minimizes the sum of the squared distances of each observed response to its fitted value. While logistic regression is based on Maximum Likelihood Estimation which says coefficients should be chosen in such a way that it maximizes the Probability of Y given X (likelihood)
Please note there are more than 10 difference between these two techniques, refer the link below -
Tutorial : Linear vs. Logistic Regression
6. How to handle missing values?
We fill/impute missing values using the following methods. Or make missing values as a separate category.
- Mean Imputation for Continuous Variables (No Outlier)
- Median Imputation for Continuous Variables (If Outlier)
- Cluster Imputation for Continuous Variables
- Imputation with a random value that is drawn between the minimum and maximum of the variable [Random value = min(x) + (max(x) - min(x)) * ranuni(SEED)]
- Impute Continuous Variables with Zero (Require business knowledge)
- Conditional Mean Imputation for Continuous Variables
- Other Imputation Methods for Continuous - Predictive mean matching, Bayesian linear regression, Linear regression ignoring model error etc.
- WOE for missing values in categorical variables
- Decision Tree, Random Forest, Logistic Regression for Categorical Variables
- Decision Tree, Random Forest works for both Continuous and Categorical Variables
- Multiple Imputation Method
Tutorial : Multiple Imputation with SAS
7. How to treat outliers?
There are several methods to treat outliers -
- Percentile Capping
- Box-Plot Method
- Mean plus minus 3 Standard Deviation
- Weight of Evidence
8. Explain Dimensionality / Variable Reduction Techniques
Unsupervised Method (No Dependent Variable)
- Principal Component Analysis (PCA)
- Hierarchical Variable Clustering (Proc Varclus in SAS)
- Variance Inflation Factor (VIF)
- Remove zero and near-zero variance predictors
- Mean absolute correlation. Removes the variable with the largest mean absolute correlation. See the detailed explanation of mean absolute correlation
Supervised Method (In respect to Dependent Variable)
For Binary / Categorical Dependent Variable
- Information Value
- Wald Chi-Square
- Random Forest Variable Importance
- Gradient Boosting Variable Importance
- Forward/Backward/Stepwise - Variable Significance (p-value)
- AIC / BIC score
For Continuous Dependent Variable
- Adjusted R-Square
- Mallows' Cp Statistic
- Random Forest Variable Importance
- AIC / BIC score
- Forward / Backward / Stepwise - Variable Significance
9. Explain equation of logistic regression model
10. What is multicollinearity and how to deal it?
Multicollinearity implies high correlation between independent variables. It is one of the assumptions in linear and logistic regression. It can be identified by looking at VIF score of variables. VIF > 2.5 implies moderate collinearity issue. VIF >5 is considered as high collinearity.
It can be handled by iterative process : first step - remove variable having highest VIF and then check VIF of remaining variables. If VIF of remaining variables > 2.5, then follow the same first step until VIF < =2.5
11. How VIF is calculated and interpretation of it?
VIF measures how much the variance (the square of the estimate's standard deviation) of an estimated regression coefficient is increased because of collinearity. If the VIF of a predictor variable were 9 (√9 = 3) this means that the standard error for the coefficient of that predictor variable is 3 times as large as it would be if that predictor variable were uncorrelated with the other predictor variables.
Steps of calculating VIF
- Run linear regression in which one of the independent variable is considered as target variable and all the other independent variables considered as independent variables
- Calculate VIF of the variable. VIF = 1/(1-RSquared)
12. Do we remove intercepts while calculating VIF?
13. What is p-value and how it is used for variable selection?
The p-value is lowest level of significance at which you can reject null hypothesis. In the case of independent variables, it implies whether coefficient of a variable is significantly different from zero,
14. How AUC, Concordance and Discordance are calculated?
Tutorial : Calculating AUC, Concordance, Discordance
15. Explain important model performance statistics
- AUC > 0.7. No significant difference between AUC score of training vs validation.
- KS should be in top 3 deciles and it should be more than 30
- Rank Ordering. No break in rank ordering.
- Same signs of parameter estimates in both training and validation
16. Explain Gain and Lift Charts
Check out this tutorial : Understanding Gain and Lift Charts
17. Explain collinearity between continuous and categorical variables. Is VIF a correct method to compute collinearity in this case?
Collinearity between categorical and continuous variables is very common. The choice of reference category for dummy variables affects multicollinearity. It means changing the reference category of dummy variables can avoid collinearity. Pick a reference category with highest proportion of cases.
VIF is not a correct method in this case. VIFs should only be run for continuous variables. The t-test method can be used to check collinearity between continuous and dummy variable.
We can also safely ignore collinearity between dummy variables. To avoid high VIFs in this case, just choose a reference category with a larger fraction of the cases
18. Assumptions of Linear Regression Model
Linear Regression Explained
19. How WOE and Information Value are calculated?
WOE and Information Value Explained
20. Difference between Factor Analysis and PCA?
- In Principal Components Analysis, the components are calculated as linear combinations of the original variables. In Factor Analysis, the original variables are defined as linear combinations of the factors.
- Principal Components Analysis is used as a variable reduction technique whereas Factor Analysis is used to understand what constructs underlie the data.
- In Principal Components Analysis, the goal is to explain as much of the total variance in the variables as possible. The goal in Factor Analysis is to explain the covariances or correlations between the variables.
21. What would happen if you define event incorrectly while building a model?
Suppose your target variable is attrition. It's a binary variable - 1 refers to customer attrited and 0 refers to active customer. In this case, your desired outcome is 1 in attrition since you need to identify customers who are likely to leave.
Let's say you set 0 as event in the logistic regression.
 |
| Logistic Regression Output. |
- The sign of estimates would be opposite which imply opposite behavior of variables towards target variable (as shown in the image above).
- Area under curve (AUC), Concordance and Discordance scores would be exactly same. No change.
- Sensitivity and Specificity score would be swapped (see the image below).
- No change in Information Value (IV) of variables.
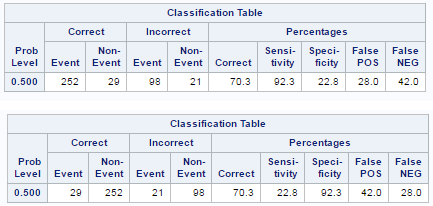 |
| Sensitivity and Specificity |
22. What is Fisher Scoring in Logistic Regression?
Logistic regression estimates are calculated by maximizing the likelihood function. The maximization of the likelihood is obtained by an iterative method called Fisher's scoring. It's an optimization technique. In general, there are two popular iterative methods for estimating the parameters of a non-linear equations. They are as follows -
- Fisher's Scoring
- Newton-Raphson
The algorithm completes when the convergence criterion is satisfied or when the maximum number of iterations has been reached. Convergence is obtained when the difference between the log-likelihood function from one iteration to the next is small.
Technical Interview Questions on SAS and R
The following is a list of SAS/R technical interview questions that are generally asked. It includes some tricky questions which requires hands-on experience.
SAS
- Difference between INPUT and PUT Functions
- How to generate serial numbers with SAS
- Difference between WHERE and IF statements
- Difference between '+' operator and SUM Function
- Use of COALESCE Function
- Difference between FLOOR and CEIL functions
- How to use arrays to recode all the numeric variables
- Number of ways you can create macro variables
- Difference between MERGE and SQL Joins
- How to calculate cumulative sum in SAS
You would find answers of the above questions in the links below -
R
- Difference between sort() and order() functions
- Popular R packages for decision tree
- How to transpose data in R
- How to remove duplicates in R
- Popular packages to handle big data
- How to perform LEFT join in R
- How R handles missing values
- How to join vertically two data frames
- Use of with() and by() functions
- Use of which() function
Check out the link below for solutions of the above questions plus other interview questions on R
SQL and Excel
Prior to interview, you can also look at questions on SQL concepts and Advanced Excel. SQL and Excel are still the most widely used tools for basic and intermediate analytics.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Very useful.
ReplyDeleteThanks, this post is very helpfull.
ReplyDeleteOne of the best website for analytics professional.
ReplyDeleteHi,
ReplyDeleteI am not able to open any link mentioned e.g Detailed Tutorial : Model Performance at point 15.
hi, so i am removing multicolinearity btwn continuous variable via VIF and factor loading. can i use same approach for categorical variable as well?
ReplyDeletei am not very clear with answer of question17, can you pls elaborate. thanks in advance.
ReplyDeleteExtremely helpful...Can you please elaborate whether it is possible to merge datasets with duplicates/duplicate IDs
ReplyDeleteReally Useful
ReplyDeleteIs this post useful for credit risk analyst job
ReplyDelete