The article below explains how to select or remove columns (variables) from dataframe in R. In R, there are multiple ways to select or delete a column.
The following code creates a sample data frame that is used for demonstration.
set.seed(456)
mydata <- data.frame(a=letters[1:5], x=runif(5,10,50), y=sample(5), z=rnorm(5))
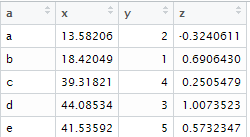 |
| Sample Data |
R : Remove column by name
In base R there are multiple ways to delete columns by name.
Method I : subset() function
The most easiest way to remove columns is by using subset() function. In the code below, we are telling R to drop variables x and z. The '-' sign indicates dropping variables. Make sure the variable names would NOT be specified in quotes when using subset() function.
df = subset(mydata, select = -c(x,z) )
a y 1 a 2 2 b 1 3 c 4 4 d 3 5 e 5
Method II : ! sign
In this method, we are creating a character vector named drop in which we are storing column names x and z. Later we are telling R to select all the variables except the column names specified in the vector drop. The function names() returns all the column names and the '!' sign indicates negation.
drop <- c("x","z")It can also be written like : df = mydata[,!(names(mydata) %in% c("x","z"))]
df = mydata[,!(names(mydata) %in% drop)]
R : Remove columns by column index numbers
It's easier to remove columns by their position number. All you just need to do is to mention the column index number. In the following code, we are telling R to delete columns that are positioned at first column, third and fourth columns. The minus sign is to drop variables.
df <- mydata[ -c(1,3:4) ]
x 1 13.58206 2 18.42049 3 39.31821 4 44.08534 5 41.53592
keeps <- c("x","z")The above code is equivalent to df = mydata[c("x","z")]
df = mydata[keeps]
df = subset(mydata, select = c(x,z))
In this case, we are telling R to keep only variables that are placed at second and fourth position.
df <- mydata[c(2,4)]
Select or Delete columns with dplyr package
In R, the dplyr package is one of the most popular package for data manipulation. It makes data wrangling easy. You can install package by using the command below -install.packages("dplyr")
library(dplyr)
mydata2 = select(mydata, -1, -3:-4)
mydata2 = select(mydata, -a, -x, -y)
mydata2 = select(mydata, -c(a, x, y))
mydata2 = select(mydata, -a:-y)
mydata2 = select(mydata, a, y:z)
Remove Columns by Name Pattern
The code below creates data for 4 variables named as follows :INC_A SAC_A INC_B ASD_A
mydata = read.table(text="
INC_A SAC_A INC_B ASD_A
2 1 5 12
3 4 2 13
", header=TRUE)
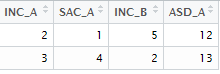 |
| Keep / Drop Columns by pattern |
mydata1 = mydata[,grepl("^INC",names(mydata))]The grepl() function is used to search for matches to a pattern. In this case, it is searching "INC" at starting in the column names of data frame mydata. It returns INC_A and INC_B.
The '!' sign indicates negation. It returns SAC_A and ASD_A.
mydata2 = mydata[,!grepl("^INC",names(mydata))]
mydata12 = mydata[,grepl("_A$",names(mydata))]
mydata22 = mydata[,!grepl("_A$",names(mydata))]
mydata32 = mydata[,grepl("*S",names(mydata))]
The same logic can be applied to a word as well if you wish to find out columns containing a particular word. In the example below, we are trying to keep columns where it contains C_A and creates a new dataframe for the retained columns.
mydata320 = mydata[,grepl("*C_A",names(mydata))]
mydata33 = mydata[,!grepl("*S",names(mydata))]
df= data.frame(x=c(1,2,3,NA,NA), y=c(5,NA,3,NA,NA), Z=c(5,3,3,4,NA))
x y Z 1 1 5 5 2 2 NA 3 3 3 3 3 4 NA NA 4 5 NA NA NA
sapply function is an alternative of for loop. It runs a built-in or user-defined function on each column of data frame. sapply(df, function(x) mean(is.na(x))) returns percentage of missing values in each column in your dataframe.
df = df[,!sapply(df, function(x) mean(is.na(x)))>0.5]The above program removed column Y as it contains 60% missing values more than our threshold of 50%. Output is given below.
x Z 1 1 5 2 2 3 3 3 3 4 NA 4 5 NA NA
The following program automates selecting or deleting columns from a data frame.
KeepDrop = function(data=df,cols="var",newdata=df2,drop=1) {
# Double Quote Output Dataset Name
t = deparse(substitute(newdata))
# Drop Columns
if(drop == 1){
newdata = data [ , !(names(data) %in% scan(textConnection(cols), what="", sep=" "))]}
# Keep Columns
else {
newdata = data [ , names(data) %in% scan(textConnection(cols), what="", sep=" ")]}
assign(t, newdata, .GlobalEnv)
}
To keep variables 'a' and 'x', use the code below. The drop = 0 implies keeping variables that are specified in the parameter "cols". The parameter "data" refers to input data frame. "cols" refer to the variables you want to keep / remove. "newdata" refers to the output data frame.
KeepDrop(data=mydata,cols="a x", newdata=dt, drop=0)
To drop variables, use the code below. The drop = 1 implies removing variables which are defined in the second parameter of the function.
KeepDrop(data=mydata,cols="a x", newdata=dt, drop=1)

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
df =df[,-c(21,6,5,7,15,2,3)]
ReplyDeletethis can work too
these no. are the column number
Great summary, thank you!
ReplyDeleteThank you for stopping by my blog!
DeleteBest computer science site ever, Thank you from Quito Ecuador.
ReplyDeleteThank you for your appreciation!
DeleteGood examples !!!!
ReplyDeleteIt was nice and easy to understand
ReplyDeleteHow to remove a columns which have more than 75% missing values using which()
ReplyDeleteI have added desired details in article. Thanks!
DeleteIf I want to remove all the cells containing "other" From a given data frame. How to create this dataset??
ReplyDeleteI am trying to remove columns where all variables are below a threshold of 5. Any advice?
ReplyDeleteWhat do you mean by "variables are below a threshold of 5"? Is it based on the number of rows in a variable?
DeleteVery well explained. Now I am able to do data preprocessing on my own :-). Thank You for sharing.
ReplyDeleteHi I want to ask something, I want to delete all the values in a column from all the data I do not want. More precisely, I will delete all values of that column in the data, how can I do that?
ReplyDeleteLoans$LoanID <- NA
DeleteThat didn't work. When I did the keeps portion of the code, R is giving me an undefined columns selected error. Please help me on this. The assignment is due this sunday so would appreciate a response by tomorrow.
ReplyDeleteThanks! This helped me out
ReplyDeleteI think that there is an error in your example titled "R : Delete column by name: Method II". Your code is: ```df = mydata[,!(names(mydata) %in% drop)]``` but I think it should be ```df = mydata[,!!(names(mydata) %in% drop)]``` I tried it the first way and couldn't get it to work but then after searching around on other sites found a suggestion that !! is correct. Maybe this is not always true but it helped me.
ReplyDeleteActually, I was able to make both methods work!
DeleteQuick question... how to user subset(eastTable, select = -c(GB, PA/G, SRS)) and make it work for the column name "PA/G"?
ReplyDeleteit brings - object 'PA' not found
Very helpful. Thank you very much.
ReplyDelete'%<-dropCol%' <- function(df,colNames){
ReplyDeletecolNames <- colNames[which(colNames %in% colnames(df))]
if(length(colNames)){
eval.parent(substitute(df <- df[,-which(colnames(df) %in% colNames)]))
}
}
mtcars %<-dropCol% "cyl"