This tutorial explains what KS statistic is and how it is calculated, along with Python code.
What is KS Statistic?
KS test stands for Kolmogorov–Smirnov test which compares the two cumulative distributions and returns the maximum difference between them. It is a non-parametric test which means you don't need to test any assumption related to the distribution of data.
In KS test, Null hypothesis states that both cumulative distributions are similar. Rejecting the null hypothesis means cumulative distributions are different.
In data science, it compares the cumulative distribution of events and non-events and KS is where there is a maximum difference between the two distributions. In simple words, it helps us to understand how well our predictive model is able to discriminate between events and non-events.
Example : Suppose you are building a propensity model in which objective is to identify prospects who are likely to buy a specific product. In this case, dependent (target) variable is in binary form which has only two outcomes : 0 (Non-event) or 1 (Event). "Event" means people who purchased the product. "Non-event" refers to people who didn't buy the product. KS test statistic measures whether model is able to distinguish between prospects and non-prospects.
Two Ways to Measure KS Test
Method 1 : Decile Method
Please refer the following steps to calculate KS statistic for validating binary predictive model.
- You need to have two variables before calculating KS. One is dependent variable which should be binary. Second one is predicted probability score which is generated from statistical model.
- Create deciles based on predicted probability columns which means dividing probability into 10 parts. First decile should contain highest probability score.
- Calculate the cumulative % of events and non-events in each decile and then compute the difference between these two cumulative distribution.
- KS is where the difference is maximum
- If KS is in top 3 decile and score above 40, it is considered a good predictive model. At the same time it is important to validate the model by checking other performance metrics as well to confirm that model is not suffering from overfitting problem.
Step 1 : Import Data and Required Libraries
I have prepared a sample data for example. The dataset contains two columns called y and p. y is a dependent variable. p refers to predicted probability.
import pandas as pd
import numpy as np
df = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
Step 2 : Run the following python function for KS Statistic.
def ks(data=None,target=None, prob=None):
data['target0'] = 1 - data[target]
data['bucket'] = pd.qcut(data[prob], 10)
grouped = data.groupby('bucket', as_index = False)
kstable = pd.DataFrame()
kstable['min_prob'] = grouped.min()[prob]
kstable['max_prob'] = grouped.max()[prob]
kstable['events'] = grouped.sum()[target]
kstable['nonevents'] = grouped.sum()['target0']
kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True)
kstable['event_rate'] = (kstable.events / data[target].sum()).apply('{0:.2%}'.format)
kstable['nonevent_rate'] = (kstable.nonevents / data['target0'].sum()).apply('{0:.2%}'.format)
kstable['cum_eventrate']=(kstable.events / data[target].sum()).cumsum()
kstable['cum_noneventrate']=(kstable.nonevents / data['target0'].sum()).cumsum()
kstable['KS'] = np.round(kstable['cum_eventrate']-kstable['cum_noneventrate'], 3) * 100
#Formating
kstable['cum_eventrate']= kstable['cum_eventrate'].apply('{0:.2%}'.format)
kstable['cum_noneventrate']= kstable['cum_noneventrate'].apply('{0:.2%}'.format)
kstable.index = range(1,11)
kstable.index.rename('Decile', inplace=True)
pd.set_option('display.max_columns', 9)
print(kstable)
#Display KS
from colorama import Fore
print(Fore.RED + "KS is " + str(max(kstable['KS']))+"%"+ " at decile " + str((kstable.index[kstable['KS']==max(kstable['KS'])][0])))
return(kstable)
mydf = ks(data=df,target="y", prob="p")
datarefers to pandas dataframe which contains both dependent variable and probability scores.targetrefers to column name of dependent variableprobrefers to column name of predicted probablity
It returns information of each decile in tabular format and also prints the KS score below the table. It also generates table in a new dataframe.
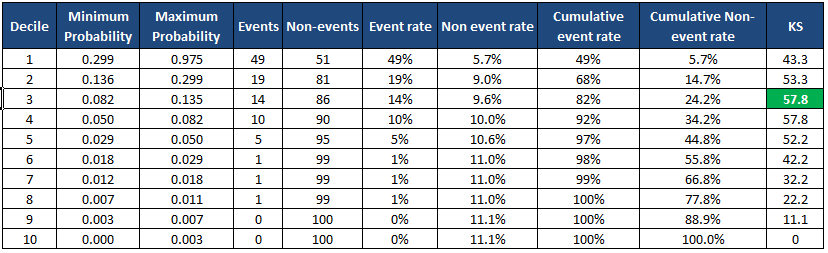
min_prob max_prob events nonevents event_rate nonevent_rate \
Decile
1 0.298894 0.975404 49 51 49.00% 5.67%
2 0.135598 0.298687 19 81 19.00% 9.00%
3 0.082170 0.135089 14 86 14.00% 9.56%
4 0.050369 0.082003 10 90 10.00% 10.00%
5 0.029415 0.050337 5 95 5.00% 10.56%
6 0.018343 0.029384 1 99 1.00% 11.00%
7 0.011504 0.018291 1 99 1.00% 11.00%
8 0.006976 0.011364 1 99 1.00% 11.00%
9 0.002929 0.006964 0 100 0.00% 11.11%
10 0.000073 0.002918 0 100 0.00% 11.11%
cum_eventrate cum_noneventrate KS
Decile
1 49.00% 5.67% 43.3
2 68.00% 14.67% 53.3
3 82.00% 24.22% 57.8
4 92.00% 34.22% 57.8
5 97.00% 44.78% 52.2
6 98.00% 55.78% 42.2
7 99.00% 66.78% 32.2
8 100.00% 77.78% 22.2
9 100.00% 88.89% 11.1
10 100.00% 100.00% 0.0
KS is 57.8% at decile 3
Method 2 : KS Two Sample Test
By using scipy python library, we can calculate two sample KS Statistic. It has two parameters - data1 and data2. In data1, We will enter all the probability scores corresponding to non-events. In data2, it will take probability scores against events.
from scipy.stats import ks_2samp
df = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
ks_2samp(df.loc[df.y==0,"p"], df.loc[df.y==1,"p"])
It returns KS score 0.6033 and p-value less than 0.01 which means we can reject the null hypothesis and concluding distribution of events and non-events is different.
Output Ks_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
The KS score of method 2 is slightly different from method 1 as second one is calculated at row level and the first one is calculated after converting data into ten parts.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Thanks for your sharing. It's worth reading it.
ReplyDeleteHi Author , Thanks for the info shared on your website.
ReplyDeleteWell done!!!
ReplyDeleteinteresting article, when we are calculating the data drift using K-S test , how can we get the strength of the distribution like how strong is the relation of two columns. you answer would be of great help
ReplyDelete