There are several ways by which you can overcome class imbalances problem in a predictive model.
Total Cost = (FN × CFN) + (FP × CFP)
Increase the case weights for the samples in the minority classes. It applies to each observation.
Weights based on the size of the risk
1. Adjusting Prior Probabilities
Prior probability is the proportion of events and non-events in the imbalance classes. Using more balanced priors or a balanced training set may help deal with a class imbalance.
In CART, you can specify prior probability assigned to each class to adjust the importance of misclassifications for each class.
library(rpart)
library(rattle)
data(audit)
audit.rpart <- rpart(Adjusted ~ .,data=audit[,-12],parms=list(prior=c(.5,.5)))
2. Cost Sensitive Training / Loss Learning
It employs the misclassification costs into the learning algorithm. In a marketing predictive model, a false positive costs just one extra direct mail while a true positive may lead to conversion worth $100. In a healthcare model, a false negative screening for tuberculosis could be destructive.
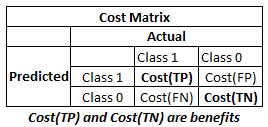
In cost-sensitive training, we assign no cost to correct classifications (Cost(TP) and Cost(TN). In other words, cost(TP) and cost(TN) are set to 0. We assign higher cost to FALSE NEGATIVE (actual event predicted as non-event) than FALSE POSITIVE as prediction to event is our objective.

library(rpart)
library(rattle)
data(audit)
loss <- matrix(c(0, 1, 20, 0), ncol=2)
audit.rpart <- rpart(Adjusted ~ ., data=audit[,-12], parms=list(loss=loss))
The cost of mis-classifying a positive example as a negative observation (FN) as 20 units and cost of mis-classifying a negative example as positive (FP) as 1 unit.
C5.0 algorithm has similar syntax to rpart by taking a cost matrix, although this function uses the transpose of the cost matrix structure used by rpart:
library(C50)
library(rattle)
data(audit)
loss <- matrix(c(0, 20, 1, 0), ncol=2)
audit.rpart <- C50(Adjusted ~ ., data=audit[,-12], parms=list(loss=loss))
library(rattle)
data(audit)
loss <- matrix(c(0, 20, 1, 0), ncol=2)
audit.rpart <- C50(Adjusted ~ ., data=audit[,-12], parms=list(loss=loss))
3. Sampling
You can perform oversampling of events i.e. reducing non-events so that ratio gets rougly equal or classes become less skewed.
4. Assigning large case weights to events
Weights based on the size of the risk
library(rpart)
library(rattle)
data(audit)
audit$weight <- abs(audit$RISK_Adjustment)/max(audit$RISK_Adjustment)*10+1
audit.rpart <- rpart(TARGET_Adjusted ~ ., data=audit[,-12], weights=weight)
 |
| Case Weights : Rare Event Model |

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Feedback: Keep writing this site. It's super helpful.
ReplyDeleteDeepanshu thanks for the article, I just beg if could you please check the "Deepanshu" data frame as it is not recognized in R.
ReplyDeleteHello bro, can you write one article in imbalanced datasets treatment from python? I would be appreciate if you would think on it!!
ReplyDelete
ReplyDeleteTo address class imbalances in predictive models, consider adjusting prior probabilities by balancing classes or using more balanced priors. In CART, specifying prior probabilities for each class can adjust misclassification importance.