Marketing Mix Modeling (MMM) is one of the most popular analysis under Marketing Analytics which helps organizations in estimating the effects of spent on different advertising channels (TV, Radio, Print, Online Ads etc) as well as other factors (price, competition, weather, inflation, unemployment) on sales. In simple words, it helps companies in optimizing their marketing investments which they spent in different marketing mediums (both online and offline).

It answers the following questions which management generally wants to know.
- Which marketing medium (TV, radio, print, online ads) returns maximum return (ROI)?
- How much to spend on marketing activities to increase sales by some percent (15%)?
- Predict sales in future from investment spent on marketing activities
- Identifying Key drivers of sales (including marketing mediums, price, competition, weather and macro-economic factors)
- How to optimize marketing spend?
- Is online marketing medium better than offline?
Imagine you are a chief strategist and your role requires you to come up with strategies that can boost company's revenue growth and profitability. With the use of insights from marketing mix model, you know sales can be increased by 50 million dollars for every 5 million dollars you spend on advertising. MMM would also help you to determine how much to spend on each advertising medium to get maximum return on investment (ROI).
According to 2018 marketing data from Statista, the U.S. spent $197.47 billion on advertising, followed by china with $79.08 billion spent. You might be curious to know the distribution of this spent by online and offline advertising. Here we go -
If you just go by "Percentage of total spend to advertising by industries", you would find answer of the question in which industry or sector marketing mix modeling is more common. As shown in the chart below, retail industry allocates the highest percentage of total spend to advertising. Chart source : brafton.com

Types of Marketing Mediums
Let's break it into two parts - offline and online.
- Print Media : Newspaper, Magazine
- TV
- Radio
- Out-of-home (OOH) Advertising like Billboards, ads in public places.
- Direct Mail like catalogs, letters
- Telemarketing
- Below The Line Promotions like free product samples or vouchers
- Sponsorship
- Search Engine Marketing like Content Marketing, Backlink building etc.
- Pay per Click, Pay per Impression
- Email Marketing
- Social Media Marketing (Facebook, YouTube, Instagram, LinkedIn Ads)
- Affiliate Marketing
Data Required for Marketing Mix Modeling
To build robust and accurate MMM model, we need data of different types. See the details below.
- Product Data refers to product and sub-product information along with price and no of units sold / unsold. It is required to understand various aspects related to product - Whether it is a new product, which product category the product falls into? Is it the largest selling product? At what rate sales of this product is growing? What's the price for each product in the category?
- Promotion Data includes details about days when promotion or offers were active and the offer type like free delivery, cash back etc.
- Advertising Data is used to measure how effective advertisement is running. In TV Advertising, Gross Rating Point (GRP) is a method which measures total audience exposure to advertisement. You can also include other traditional methods such as Newspapers and Magazines and Radio. You can include SPENDS which is dollar value spent on these methods. Digital marketing is popular these days and a large percentage of population can access internet now which opens up a whole new world for advertising. We can use the variables like Digital Spend, Affiliation Marketing Spend, Content Marketing Spend, Sponsorship Spend and Social Media Spend to capture online media investment information.
- Seasonality : Increase in sales due to seasonality can make calculation of identifying top drivers of sales biased. We would not be able to assess the impact of promotion on sales. For example, sales in woolen jackets will be higher in winter season than summer. We also need to incorporate holidays and major events planned in a particular month. For example, sales during Christmas season is generally high than average sales.
- Geographical Data : It refers to location of retail store. It can be city, state or postal code of store.
- Macroeconomic Data : Sales can also be affected by macro economic factors like inflation, unemployment rate, GDP etc. Companies generally report negative growth rate in sales during recession. We need to incorporate these factors in our model so that it understands recession and cyclical effects.
- Sales : It is not possible to build MMM without sales variable. Sales can be in volume in units as well as revenue($)
Till now we have covered what data points we need for building the model. The question arises from where we get these data points. We need to extract data from multiple sources and the merge them to prepare analytics datamart for modeling.
- Sales, product and promotion data are generally stored internally within company's relational databases management system.
- Advertising data is either managed by internal marketing team or through external marketing agency.
- Macroeconomic data can be extracted through websites like World Bank, IMF and Economagic.
Data Preparation
First we need to check how granular data we have. At which level we have sales and advertising data in our database? Is it at hourly / daily or weekly level? Some data points can be at monthly level, while others are measured every week. We need to be very careful while merging data from multiple sources. Data aggregation comes into picture here. Suppose some variables are captured daily. They can be aggregated to weekly level by summing them up or taking average (whichever makes sense). Question arises how to decide the level of data for modeling.
The level of data can be decided depending on the implementation of promotion campaign. Ideally data should NOT be prepared at daily level as daily sales data generally has too much variation which leads to poor accuracy. We generally use weekly time period and aggregate data at weekly level as promotions are live from Monday to Sunday.
Another question : Do we have data at product level which means product information in each invoice? See the example below.
+----------------+------------------+-------------+--------------+-------+
| Transaction ID | Transaction Date | Customer ID | Product Code | Sales |
+----------------+------------------+-------------+--------------+-------+
| 1 | 24-09-2019 | 12 | AAA | 824 |
| 1 | 24-09-2019 | 12 | AAB | 809 |
+----------------+------------------+-------------+--------------+-------+
If you observe the above table, you would see transaction data at daily level. We can transform it to weekly level without losing any required information. Transformed data contains number of distinct customers, no of transactions, total sales of different products in each week.
+------+--------------------+--------------+-----------+-----------+
| Week | Distinct Customers | Transactions | Sales AAA | Sales AAB |
+------+--------------------+--------------+-----------+-----------+
Sales (dollar value) is generally considered as a dependent variable in MMM. Sales into two components: baseline sales (sales when no promotions or offers are active) and incremental sales (due to marketing activities). In eCommerce industry, sales is also called as Gross Merchandise Volume (GMV). Sometimes companies consider sales volume (in units) as a target variable. In some cases Web Traffic or App Downloads are also considered.
Data Exploration and Transformation
Before building a model, we as analysts need to perform various quality checks. It's a crucial stage of building a model. If your data is not prepared and handled correctly, model development would be of less use. Accuracy and robustness of model can also be deteriorated badly if you compromise data cleaning and transformation.
- Importing Data : If you have data in CSV or Excel format, you need to load data into R/Python. After importing data, you need to ensure whole data have been loaded correctly by checking the number of rows and columns. Length of character variables can be truncated while importing.
- Missing Values : It is important to check the number of missing values in each variable. Many statistical algorithms are not immune to missing values. They simply remove the rows when missing values exist. It can cause a loss of a good amount of data depending on percentage of missing values. Sometimes missing values are specially coded as '999'. We also need to understand the reason behind missing data. Is it a genuine missing because it is not applicable to some customers? Or customers or respondents did not provide the information? Missing values can be treated by replacing them with mean, median or mode value. We can also remove missing values if it constitutes a very small percentage of data. Moving average is also a common technique to impute missing values when data is in time series format.
- Outlier Values are referred to as extreme values (in plain English). For example, customer having 150 years age is an outlier.
Sometimes data are entered incorrectly into the system. We can handle outliers by percentile capping at 99th or 95th percentile depending on the distribution. Outliers can also be removed if percentage of these kind of observations in the dataset is very small.
- Univariate and Bivariate Analysis are ways to perform data exploration. Univariate analysis refers to examine the distribution of a single variable. It can be done by calculating mean, median, mode, standard deviation and percentiles. Bivariate analysis refers to checking the association between two variables. For example, inspecting relationship between TV GRPs and Sales.
Adstock
The concept behind Adstock is that advertising has been shown to have an effect extending several periods after you see it first time. In other words, an advertisement from a previous period may have some effect of an advertisement in the current period. It is also called advertising carryover. It's a very old concept (first used in 1980s) when TV was the main medium of advertisement. It is not restricted to TV only and can be applied to online, radio and print media as well. Let's understand through example.
Suppose you are watching your favorite TV show. During commercial breaks, you see an ad of perfume brand 'X'. You would not buy this perfume immediately after the commercial break. Let's say you see the ad of the same brand 'X' a couple of times in next few days. It would increase awareness to a new level and there is a high chance that you would purchase perfume of this brand (if you need it). If you would not have seen the advertisement again after first time, you would not be able to recall the brand easily. This is the decay effect of Adstock. This decay is reduced by new advertising exposure.
Ads shown on TV are generally remembered for longer than online ads
At = Tt + λAt −1 + λAt −2 Here t =1,...,n
Where At is the Adstock at time t. Tt is the value of the advertising variable at time t and λ is the 'retention' or lag weight parameter and can be interpreted as percentage of effectively remembered ad contact from previous week plus contacts from current week. λ lies between 0 and 1. Let's learn via example.
Adstock rate = 0.5 TV GRP in week 1 = 115 TV GRP in week 2 = 120 Adstock in week 2 = 120 + 0.5*115 = 177.5
Techniques used in Marketing Mix Modeling
The common statistics techniques used in MMM are linear and non-linear regression techniques.Multiple Linear Regression Sales = β0 + β1*X1 + β2*X2 + .... + βn*Xn Xi are independent variables (or predictors), βi can be interpreted as change in sales corresponding to unit change in predictor.
Log-Linear Regression LN(Sales) = β0 + β1*X1 + β2*X2 + .... + βn*Xn LN is natural log. Xi are independent variables (or predictors), βi can be interpreted as % change in sales corresponding to unit change in predictor.
Log-Log Regression LN(Sales) = β0 + β1*LN(X1) + β2*LN(X2) + .... + βn*LN(Xn) βi can be interpreted as % change in sales corresponding to 1% change in predictor.
Elasticity
Elasticity answer this question "What marketing activities to pull or push and the corresponding impact on sales". For example a price elasticity of -1.9 means that when price is increased by 1%, sales will be reduced by 1.9 percent keeping all other factors being constant. Similarly we can calculate elasticity of TV, radio and online advertisement.
When you have simple linear regression model, you can calculate elasticity using the formula below -
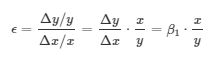
In the case of non-linear regression models, the above defined elasticity formula needs to be tweaked according to the equation. Refer the table below.

Model Performance
Model performance of MMM can be checked like we do in any linear regression model. Common model performance metrics are R-Squared, Adjusted R-Squared, Mean Absolute Percentage Error (MAPE) etc.
It explains the percentage of variation explained by the model. It generally lies between 0 and 1 but it can be negative in rare situations. Higher the R-squared, better the model.
The problem with R-squared is it always increase when new independent variable is added into the model. It does not matter whether newly added variable improves or deteriorates the model. To overcome this issue, Adjusted R-squared comes into picture and it increases only if a newly-added variable improves the model.
When your data is in time series, MAPE is the most common method to measure model performance. It measures how accurate forecast of MMM is. Model having MAPE less than 10% is considered as a good model.
Marketing Mix Modeling using SAS, Python and R
In the program below, I have shown how to implement basic MMM model using SAS, R and Python. This model takes takes into account three variables which are price and exposure on two different advertising mediums (let's say TV and online). You can download dataset from this link
R Code
# Read CSV File
df <- read.csv("Furniture.csv")
adstock <- function(data, rate) {
return(as.numeric(filter(x=data, filter=rate, method="recursive")))
}
x1 <- adstock(df$Advt1, 0.5)
x2 <- adstock(df$Advt2, 0.5)
# Model
mod <- lm(formula=Sales ~ x1 + x2 + Price.Furniture,data=df)
summary(mod)
# Price Elasticity
(PE <-as.numeric(mod$coefficients["Price.Furniture"] * mean(df$Price.Furniture)/mean(df$Sales)))
Python Code
import pandas as pd
df = pd.read_csv("C:/Users/DELL/Documents/Furniture.csv")
#Adstock
import numpy as np
def adstock(data, rate):
tt = np.empty(len(data))
tt[0] = data[0]
for i in range(1, len(data)):
tt[i] = data[i] + tt[i-1] * rate
return tt
x1 = adstock(df.Advt1, 0.5)
x2 = adstock(df.Advt2, 0.5)
#Linear Regression Model
from sklearn.linear_model import LinearRegression
x = pd.DataFrame({"x1":x1, "x2":x2, "Price": df["Price.Furniture"]})
y = df.iloc[:,0]
lm = LinearRegression()
lm = lm.fit(x,y)
coefficients = pd.concat([pd.DataFrame(x.columns),pd.DataFrame(np.transpose(lm.coef_))], axis = 1)
lm.intercept_
#Elasticity
coefficients.iloc[2,1] * np.mean(x.Price) / np.mean(y)
SAS Code
FILENAME PROBLY TEMP;
PROC HTTP
URL="https://raw.githubusercontent.com/deepanshu88/Datasets/master/Furniture.csv"
METHOD="GET"
OUT=PROBLY;
RUN;
OPTIONS VALIDVARNAME=ANY;
PROC IMPORT
FILE=PROBLY
OUT=WORK.MMM (rename='Price.Furniture'n=Price) REPLACE
DBMS=CSV;
RUN;
%let adstock = 0.5;
data Adstock;
set MMM;
format x1 x2 10.2;
if _N_ = 1 then do;
x1 = Advt1;
x2 = Advt2;
retain x1 x2;
end;
else do;
x1 = sum(Advt1, x1*&adstock.);
x2 = sum(Advt2, x2*&adstock.);
end;
run;
ods output ParameterEstimates = coefficients ;
proc reg data=adstock;
model sales = x1 x2 Price;
run;
proc sql;
select estimate into: beta from coefficients where Variable = 'Price';
select mean(sales) into: meansales from MMM;
select mean(Price) into: meanprice from MMM;
quit;
%let elasticity = %sysevalf(&beta. *(&meanprice./&meansales.));
%put &elasticity.;
The above code returns elasticity value of -1.796211 which means increase in price of furniture by 1% will decrease the sales of furniture by 1.79%.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Love your work. Do you have SAS code for MMM?
ReplyDeleteThanks.
Ethan
Yes I have added in the article. Thanks!
DeleteCould you also address how to use "proc mixed" and "proc GAM" in MMM given that the lower geographic data are available?
ReplyDeleteThanks.
Good question.. But, more interesting how to get positive coefficients for all marketing drivers?
ReplyDelete@Deepanshu- Nice post, very concise. I dont understand one thing though- Mix models differ from simple Linear models in that they allow both fixed and random effects. Where do you capture these in your equation.
ReplyDeleteThose are mixed models - a statistical term. The post is about marketing mix models, that is modeling of how marketing mix impacts sales
DeleteExcellent job done. Thanks.
ReplyDeleteHi!
ReplyDeleteHow do you calculate the variable contributions in log-linear and log-log models? It's easy in case of additive one.
Excellent post , does any body have data needed for Marketing mix model?
ReplyDeleteHi! Fascinating article! Wonder why did you multiply the coefficient with np.mean(x.Price) / np.mean(y). I assume this way you can predict the percentage change right? Without it, it's if you decrease price by 1 USD Sales would increase by 10.0713 units.
ReplyDeletehey thank you for this post. it is really helpfull to me bu ı have question. ı am using adaboostregressior which function ı should be using for elasticity ?
ReplyDeleteThanks. So wonderful job done.
ReplyDeleteHi, can anyone elaborate on calculating saturation curves?
ReplyDeleteHi Deepanshu,
ReplyDeleteGreat article for starting and having an idea of the MMM. I have a question on Media Mix Model. I have weekly level data on affiliates,banner, social media ( lets see they are called vehicles ), most of them have a granularity for example under banner we have display, video etc. Many times they are higly correlated . How do we keep variables which have high VIF or do we really keep them in Model ?Is Transformation of those a best practise ? Business every quater would look for planning and they may want to plan all those vehicles .Let me know your thoughts.
NICE POST, THANKS
ReplyDeleteGlad you found it useful. Thanks!
Deletehi Deepanshu,
ReplyDeleteI do not have TV GRP as all my advertising channels have spend in $.How do I still find the important channels that affect the sales.
A quick response would be apprecaited.
thanks
Hi,
ReplyDeleteIf you had a model with variables without ad stock and with ad stock; does the carryover effect influence variables without adstock?
Thanks
Great blog post! The content is captivating, educational, and thoroughly researched. I value the valuable insights provided and eagerly anticipate more of your writing!
ReplyDelete