This tutorial explains how to get unique values from a column in Pandas DataFrame, along with examples.
df['columnName'].unique()
for column in df.columns:
unique_values = df[column].unique()
print(f"Unique values in column '{column}': {unique_values}")
# Loop through specified columns and find unique values
selected_columns = ['Students', 'Section']
for column in selected_columns:
unique_values = df[column].unique()
print(f"Unique values in column '{column}': {unique_values}")
df.drop_duplicates(subset=['Students', 'Section'])
Let's create a sample pandas DataFrame to explain examples in this tutorial.
import pandas as pd
df = pd.DataFrame({
'Students':["Dave","Sam","Steve","Jon","Sam","Steve","Alex"],
'Section':['A','A','A','B','B','A','B'],
'Score':[91,92,76,78,82,87,69]
})
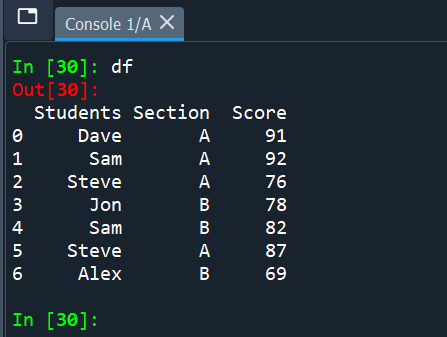
In this example, we are using the dataframe named "df" and the column of interest is "Students" which contains duplicate values.
We are using the pandas unique() function to get unique values from a column in a dataframe.
df['Students'].unique()
The unique() method returns a NumPy array of unique values.
array(['Dave', 'Sam', 'Steve', 'Jon', 'Alex'], dtype=object)Incase you want the unique values of the column as a list, you can use the tolist() function.
df['Students'].unique().tolist()
['Dave', 'Sam', 'Steve', 'Jon', 'Alex']The drop_duplicates() method is a DataFrame method that removes duplicate rows from the DataFrame and return unique values.
df.Students.drop_duplicates()
The drop_duplicates() method returns a Series or DataFrame.
0 Dave
1 Sam
2 Steve
3 Jon
6 Alex
Name: Students, dtype: object
If you want all the columns corresponding to the unique values in the column "Students", you can use the subset parameter and specify specific columns for finding duplicates.
df.drop_duplicates(subset=['Students'])
As shown in the output below, it returns a DataFrame with unique values in the "Students" column, keeping all other columns.
Students Section Score
0 Dave A 91
1 Sam A 92
2 Steve A 76
3 Jon B 78
6 Alex B 69
We can use loop to get unique values in all the columns in a dataframe one by one.
for column in df.columns:
unique_values = df[column].unique()
print(f"Unique values in column '{column}': {unique_values}")
Unique values in column 'Students': ['Dave' 'Sam' 'Steve' 'Jon' 'Alex']
Unique values in column 'Section': ['A' 'B']
Unique values in column 'Score': [91 92 76 78 82 87 69]
We can specify multiple columns from which we want to extract unique values and then run a loop to get unique values of those columns one by one. In this case, we have two columns - 'Students' and 'Section' for fetching unique values.
selected_columns = ['Students', 'Section']
# Loop through specified columns and find unique values
for column in selected_columns:
unique_values = df[column].unique()
print(f"Unique values in column '{column}': {unique_values}")
Unique values in column 'Students': ['Dave' 'Sam' 'Steve' 'Jon' 'Alex']
Unique values in column 'Section': ['A' 'B']
If you want to remove duplicates based on multiple columns, you can specify the columns in the subset argument in the drop_duplicates() function.
df.drop_duplicates(subset=['Students', 'Section'])
In the output below, you will notice that only "Steve" appears once, and the duplicate has been removed.
Students Section Score
0 Dave A 91
1 Sam A 92
2 Steve A 76
3 Jon B 78
4 Sam B 82
6 Alex B 69
To count the number of unique values, we can use the nunique() function.
# Count Unique Values in a Column df['Students'].nunique() # Count Unique Values in Multiple Columns df[['Students', 'Section']].nunique() # Count Unique Values in All Columns df.nunique()
If you want to sort the unique values from the 'Students' column, you can use the unique() method and then apply the sorted() function to the result.
sorted(df['Students'].unique())
['Alex', 'Dave', 'Jon', 'Sam', 'Steve']
Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet