
In this tutorial, you will learn how to integrate Google's Gemini AI Model into R. Google AI has an official Python package and documentation for the Gemini API but R users need not feel let down by the lack of official documentation for this API as this tutorial will provide you with the necessary information to get started using Gemini API in R.
Steps to Integrate Gemini into R
To use Google's Gemini via API in R, please follow these steps.
- Step 1 : Get API Key -
You can access the Gemini API by visiting this link : Google AI Studio. Once you have access, you can create an API key by clicking on
Create API Keybutton. Copy and save your API key for future reference.Please note that the Gemini API is currently available for free. In the future, there may be a cost involved in using the Gemini API. Check out the pricing page here.
- Step 2 : Install the Required Libraries -
Before we can start using Gemini AI Model in R, we need to install the necessary libraries. The two libraries we will be using are
httrandjsonlite. The "httr" library allows us to post our question and fetch response with Gemini API, while the "jsonlite" library helps to convert R object to JSON format.To install these libraries, you can use the following code in R:
install.packages("httr") install.packages("jsonlite") - Step 3 : Generate Content Based on Prompt -
The following function generates a response from the Gemini Model based on your question (prompt).
library(httr) library(jsonlite) # Function gemini <- function(prompt, temperature=1, max_output_tokens=1024, api_key=Sys.getenv("GEMINI_API_KEY"), model = "gemini-flash-latest") { if(nchar(api_key)<1) { api_key <- readline("Paste your API key here: ") Sys.setenv(GEMINI_API_KEY = api_key) } model_query <- paste0(model, ":generateContent") response <- POST( url = paste0("https://generativelanguage.googleapis.com/v1beta/models/", model_query), query = list(key = api_key), content_type_json(), encode = "json", body = list( contents = list( parts = list( list(text = prompt) )), generationConfig = list( temperature = temperature, maxOutputTokens = max_output_tokens ) ) ) if(response$status_code>200) { stop(paste("Error - ", content(response)$error$message)) } candidates <- content(response)$candidates outputs <- unlist(lapply(candidates, function(candidate) candidate$content$parts)) return(outputs) } prompt <- "R code to remove duplicates using dplyr." cat(gemini(prompt))When you run the function above first time, it will ask you to enter your API Key. It will save the API Key in
GEMINI_API_KEYenvironment variable so it won't ask for API key when you run the function next time.Sys.setenv( )is to store API Key whereasSys.getenv( )is to pull the stored API Key.
```r
# Remove duplicate rows from a data frame
df <- data.frame(
x = c(1, 2, 3, 4, 5, 1, 2, 3, 4, 5),
y = c("a", "b", "c", "d", "e", "a", "b", "c", "d", "e")
)
# Using `distinct()`
df %>% distinct()
```
- Prompt: Prompt means a question you want to ask. It is also called search query.
- Tokens: Tokens are subwords or words. For example, the word "lower" splits into two tokens: "low" and "er".
- Temperature: It is the model parameter which is used to fine tune the response. It lies between 0 and 2. If you set value of temperature close to 0, it means model to generate response which has highest probability. A value closer to 2 will produce responses that are more creative or random.
- Max output tokens: It is the model parameter which defines the maximum number of tokens that can be generated in the response.
The following R code returns real-time information from google search using the Gemini API.
library(jsonlite)
library(httr)
gemini_search <- function(prompt,
model = "gemini-flash-latest",
api_key = Sys.getenv("GEMINI_API_KEY")) {
if(nchar(api_key)<1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
# Define the URL
url <- paste0("https://generativelanguage.googleapis.com/v1beta",
"/models/",
model,
":generateContent?key=",
api_key)
# Create request body
body <- list(
contents = list(
list(
parts = list(
list(text = prompt)
)
)
),
tools = list(
list(
google_search = setNames(list(), character(0))
)
)
)
# Make the request
response <- POST(url,
add_headers(`Content-Type` = "application/json"),
body = toJSON(body, auto_unbox = TRUE),
encode = "json")
# Parse response
r <- content(response, "parsed", simplifyVector = TRUE)
return(r[["candidates"]][["content"]][["parts"]][[1]][["text"]])
}
# Example
cat(gemini_search("What is the current Google stock price?"))
How to Handle Image as Input
To handle image as input, we can use the gemini-flash-latest model. It helps to describe image. You can ask any question related to the image. Make sure to install "base64enc" library.
library(httr)
library(jsonlite)
library(base64enc)
# Function
gemini_vision <- function(prompt,
image,
temperature=1,
max_output_tokens=4096,
api_key=Sys.getenv("GEMINI_API_KEY"),
model = "gemini-flash-latest") {
if(nchar(api_key)<1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
model_query <- paste0(model, ":generateContent")
response <- POST(
url = paste0("https://generativelanguage.googleapis.com/v1beta/models/", model_query),
query = list(key = api_key),
content_type_json(),
encode = "json",
body = list(
contents = list(
parts = list(
list(
text = prompt
),
list(
inlineData = list(
mimeType = "image/png",
data = base64encode(image)
)
)
)
),
generationConfig = list(
temperature = temperature,
maxOutputTokens = max_output_tokens
)
)
)
if(response$status_code>200) {
stop(paste("Error - ", content(response)$error$message))
}
candidates <- content(response)$candidates
outputs <- unlist(lapply(candidates, function(candidate) candidate$content$parts))
return(outputs)
}
gemini_vision(prompt = "Describe what people are doing in this image",
image = "https://upload.wikimedia.org/wikipedia/commons/a/a7/Soccer-1490541_960_720.jpg")
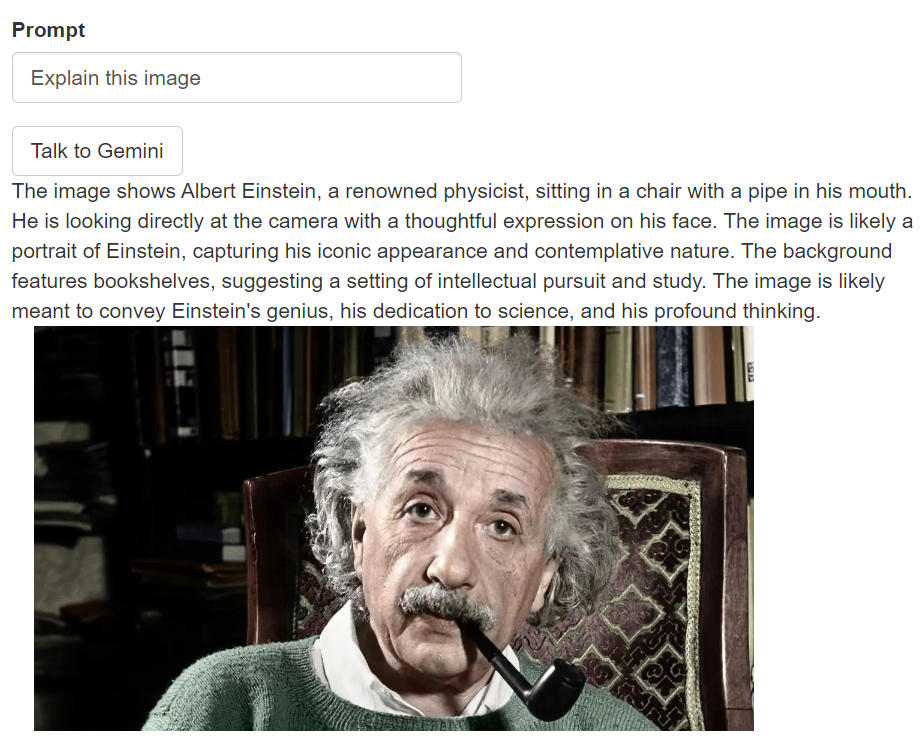
Shiny App to Explain Image using Gemini API
You can create an interactive Shiny app that describes an image uploaded by user.
library(shiny)
Sys.setenv(GEMINI_API_KEY = "xxxxxxxxxxx")
ui <- fluidPage(
mainPanel(
fluidRow(
fileInput(
inputId = "imgFile",
label = "Select image to upload",
),
textInput(
inputId = "prompt",
label = "Prompt",
placeholder = "Enter Your Query"
),
actionButton("submit", "Talk to Gemini"),
textOutput("response")
),
imageOutput(outputId = "myimage")
)
)
server <- function(input, output) {
observeEvent(input$imgFile, {
path <- input$imgFile$datapath
output$myimage <- renderImage({
list(
src = path
)
}, deleteFile = FALSE)
})
observeEvent(input$submit, {
output$response <- renderText({
gemini_vision(input$prompt, input$imgFile$datapath)
})
})
}
shinyApp(ui = ui, server = server)
Question and Answering
Suppose you have some documents. You want to make a system where people can ask questions about these documents and a chatbot will answer based on what they ask.
make_prompt <- function(query, relevant_passage) {
escaped <- gsub("'", "", gsub('"', "", gsub("\n", " ", relevant_passage)))
prompt <- sprintf("You are a helpful and informative bot that answers questions using text from the reference passage included below. \
Be sure to respond in a complete sentence, being comprehensive, including all relevant background information. \
However, you are talking to a non-technical audience, so be sure to break down complicated concepts and \
strike a friendly and conversational tone. \
If the passage is irrelevant to the answer, you may ignore it.
QUESTION: '%s'
PASSAGE: '%s'
ANSWER:
", query, escaped)
return(prompt)
}
passage <- "Title: Is AI a Threat to Content Writers?\n Author: Deepanshu Bhalla\nFull article:\n Both Open source and commercial generative AI models have made content writing easy and quick. Now you can create content in a few mins which used to take hours."
query <- "Who is the author of this article?" prompt = make_prompt(query, passage) cat(gemini(prompt))
Deepanshu Bhalla is the author of this article.
query <- "Summarize this article" prompt = make_prompt(query, passage) cat(gemini(prompt))
This article discusses whether AI is a threat to content writers. It argues that both open source and commercial generative AI models have made content writing easier and quicker, and that this could potentially put content writers out of a job.
Chat Functionality
There are many use cases where it is important for a Chatbot to remember your previous questions in order to answer subsequent questions. For example, if you ask a question like "What is 2+2?" and then follow up with the another question : "What is the square of it?", it should understand your query and respond accordingly.
library(httr)
library(jsonlite)
chat_gemini <- function(prompt,
temperature=1,
api_key=Sys.getenv("GEMINI_API_KEY"),
model="gemini-flash-latest") {
if(nchar(api_key)<1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
model_query <- paste0(model, ":generateContent")
# Add new message
chatHistory <<- append(chatHistory, list(list(role = 'user',
parts = list(
list(text = prompt)
))))
response <- POST(
url = paste0("https://generativelanguage.googleapis.com/v1beta/models/", model_query),
query = list(key = api_key),
content_type_json(),
body = toJSON(list(
contents = chatHistory,
generationConfig = list(
temperature = temperature
)
), auto_unbox = T))
if(response$status_code>200) {
chatHistory <<- chatHistory[-length(chatHistory)]
stop(paste("Status Code - ", response$status_code))
} else {
answer <- content(response)$candidates[[1]]$content$parts[[1]]$text
chatHistory <<- append(chatHistory, list(list(role = 'model',
parts = list(list(text = answer)))))
}
return(answer)
}
chatHistory <- list()
cat(chat_gemini("2+2"))
cat(chat_gemini("square of it"))
cat(chat_gemini("add 3 to result"))
> chatHistory <- list() > cat(chat_gemini(prompt="3+5")) 3+5 is equal to 8. > cat(chat_gemini(prompt="square of it")) The square of 8 is 64. > cat(chat_gemini(prompt="Add 2 to it")) 64 + 2 = 66.
How to Add System Instructions
System instructions help customize how the model behaves based on your needs. They give the model context so it can understand tasks better and provide more accurate responses.
library(httr)
library(jsonlite)
# Function
gemini <- function(prompt,
system_prompt = "",
model = "gemini-flash-latest",
google_search = FALSE,
temperature = 1,
api_key = Sys.getenv("GEMINI_API_KEY")) {
if (nchar(api_key) < 1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
# Define the URL
url <- paste0("https://generativelanguage.googleapis.com/v1beta",
"/models/",
model,
":generateContent?key=",
api_key)
# Create the base request body with the main content
body <- list(
contents = list(
list(
parts = list(
list(text = prompt)
)
)
),
generationConfig = list(
temperature = temperature
)
)
# Add systemInstruction only if system_prompt is not blank
if (nchar(system_prompt) > 0) {
body$systemInstruction <- list(
parts = list(
list(text = system_prompt)
)
)
}
# Conditionally add the search tool if google_search is TRUE
if (google_search) {
body$tools <- list(
list(
google_search = setNames(list(), character(0))
)
)
}
# Make the request
response <- POST(url,
add_headers(`Content-Type` = "application/json"),
body = toJSON(body, auto_unbox = TRUE),
encode = "json")
# Parse and return the response text
r <- content(response, "parsed", simplifyVector = TRUE)
return(r[["candidates"]][["content"]][["parts"]][[1]][["text"]])
}
prompt <- "R code to remove duplicates using dplyr."
system_prompt <- "You are an expert in R programming. Provide precise and concise response to query."
cat(gemini(prompt, system_prompt))
Thinking/Reasoning
thinking_level can be set to minimal, low, medium, or high. By default, it is set to high. While the latest Gemini models do not support completely turning thinking off, the minimal setting generally means the model is unlikely to think, though it may still perform some internal reasoning.
gemini <- function(prompt,
system_prompt = "",
model = "gemini-flash-latest",
google_search = FALSE,
temperature = 1,
thinking_level = "high",
include_thoughts = FALSE,
api_key = Sys.getenv("GEMINI_API_KEY"),
retries = 5) {
if (nchar(api_key) < 1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
# Define the URL
url <- paste0("https://generativelanguage.googleapis.com/v1beta",
"/models/",
model,
":generateContent?key=",
api_key)
# Create the base request body with the main content
body <- list(
contents = list(
list(
parts = list(
list(text = prompt)
)
)
),
generationConfig = list(
temperature = temperature
)
)
# Add systemInstruction only if system_prompt is not blank
if (nchar(system_prompt) > 0) {
body$systemInstruction <- list(
parts = list(
list(text = system_prompt)
)
)
}
# Conditionally add the search tool if google_search is TRUE
if (google_search) {
body$tools <- list(
list(
google_search = setNames(list(), character(0))
)
)
}
# Conditionally add thinkingConfig if thinking_level is provided
if (!is.null(thinking_level)) {
# Ensure thinking_level is an integer
if (!is.character(thinking_level)) {
warning("thinking_level must be a string. Skipping thinkingConfig.")
# Do not add thinkingConfig if the value is invalid
} else {
body$generationConfig$thinkingConfig <- list(
thinking_level = as.character(thinking_level),
include_thoughts = include_thoughts
)
}
}
attempt <- 1
repeat {
# Make the request
response <- POST(url,
add_headers(`Content-Type` = "application/json"),
body = toJSON(body, auto_unbox = TRUE),
encode = "json")
# Parse the response
r <- content(response, "parsed", simplifyVector = TRUE)
result <- r[["candidates"]][["content"]][["parts"]][[1]][["text"]]
sleep_time <- 10
if (!is.null(result)) {
# Return the result if the request was successful
return(result)
} else {
error_message <- r$error$message
if (attempt < retries) {
message("Error: ", error_message, " - retrying in ", sleep_time*attempt , " seconds (attempt ", attempt, " of ", retries, ")...")
Sys.sleep(sleep_time * attempt)
attempt <- attempt + 1
} else {
# Return the error message after final attempt
return(paste("Error:", error_message))
}
}
}
}
response <- gemini("Solve 2x+1=5.",
model = "gemini-flash-lite-latest",
thinking_level = "medium",
include_thoughts = TRUE,
google_search = F)
cat(response)
How to Generate Text Embeddings
In this section, we will show you how to use the Gemini API to generate text embeddings. This will help you search through a list of documents and ask questions about a certain topic.
In the example below, we have three documents on AI. We want to identify the most relevant document based on a question about the AI topic.
embedding_gemini <- function(prompt,
api_key=Sys.getenv("GEMINI_API_KEY"),
model = "gemini-embedding-2-preview") {
if(nchar(api_key)<1) {
api_key <- readline("Paste your API key here: ")
Sys.setenv(GEMINI_API_KEY = api_key)
}
model_query <- paste0(model, ":embedContent")
response <- POST(
url = paste0("https://generativelanguage.googleapis.com/v1beta/models/", model_query),
query = list(key = api_key),
content_type_json(),
encode = "json",
body = list(
model = paste0("models/",model),
content = list(
parts = list(
list(text = prompt)
))
)
)
if(response$status_code>200) {
stop(paste("Status Code - ", response$status_code))
}
return(unlist(content(response)))
}
DOCUMENT1 = "AI is like a smart helper in healthcare. It can find problems early by looking at lots of information, help doctors make plans just for you, and even make new medicines faster."
DOCUMENT2 = "AI needs to be open and fair. Sometimes, it can learn things that aren't right. We need to be careful and make sure it's fair for everyone. If AI makes a mistake, someone needs to take responsibility."
DOCUMENT3 = "AI is making school exciting. It can make learning fit you better, help teachers make fun lessons, and show when you need more help."
df <- data.frame(Text = c(DOCUMENT1, DOCUMENT2, DOCUMENT3))
# Get the embeddings of each text
embedding_out <- list()
for(i in 1:nrow(df)) {
result <- embedding_gemini(prompt = df[i,"Text"])
embedding_out[[i]] <- result
}
# Identify Most relevant document
query <- "AI can generate misleading results many times."
scores_query <- embedding_gemini(query)
# Calculate the dot products
dot_products <- sapply(embedding_out, function(x) sum(x * scores_query))
# Find the index of the maximum dot product to view the most relevant document
idx <- which.max(dot_products)
df$Text[idx]
[1] "AI needs to be open and fair. Sometimes, it can learn things that aren't right. We need to be careful and make sure it's fair for everyone. If AI makes a mistake, someone needs to take responsibility."
Refer to the following guide on Gemini Text-to-Speech capabilities.
The following code returns all the AI models available through the Gemini API.
library(httr)
library(jsonlite)
models <- GET(
url = "https://generativelanguage.googleapis.com/v1beta/models",
query = list(key = Sys.getenv("GEMINI_API_KEY")))
lapply(content(models)[["models"]], function(model) c(description = model$description,
displayName = model$displayName,
name = model$name,
method = model$supportedGenerationMethods[1]))
| Description | Name | Method |
|---|---|---|
| Gemini Flash Latest | models/gemini-flash-latest | generateContent |
| Gemini Flash-Lite Latest | models/gemini-flash-lite-latest | generateContent |
| Gemini Pro Latest | models/gemini-pro-latest | generateContent |
| Gemini 2.5 Flash | models/gemini-2.5-flash | generateContent |
| Gemini 2.5 Pro | models/gemini-2.5-pro | generateContent |
| Gemini 2.0 Flash | models/gemini-2.0-flash | generateContent |
| Gemini 2.0 Flash 001 | models/gemini-2.0-flash-001 | generateContent |
| Gemini 2.0 Flash-Lite 001 | models/gemini-2.0-flash-lite-001 | generateContent |
| Gemini 2.0 Flash-Lite | models/gemini-2.0-flash-lite | generateContent |
| Gemini 2.5 Flash Preview TTS | models/gemini-2.5-flash-preview-tts | countTokens |
| Gemini 2.5 Pro Preview TTS | models/gemini-2.5-pro-preview-tts | countTokens |
| Gemma 3 1B | models/gemma-3-1b-it | generateContent |
| Gemma 3 4B | models/gemma-3-4b-it | generateContent |
| Gemma 3 12B | models/gemma-3-12b-it | generateContent |
| Gemma 3 27B | models/gemma-3-27b-it | generateContent |
| Gemma 3n E4B | models/gemma-3n-e4b-it | generateContent |
| Gemma 3n E2B | models/gemma-3n-e2b-it | generateContent |
| Gemma 4 26B A4B IT | models/gemma-4-26b-a4b-it | generateContent |
| Gemma 4 31B IT | models/gemma-4-31b-it | generateContent |
| Gemini 2.5 Flash-Lite | models/gemini-2.5-flash-lite | generateContent |
| Nano Banana | models/gemini-2.5-flash-image | generateContent |
| Gemini 3 Pro Preview | models/gemini-3-pro-preview | generateContent |
| Gemini 3 Flash Preview | models/gemini-3-flash-preview | generateContent |
| Gemini 3.1 Pro Preview | models/gemini-3.1-pro-preview | generateContent |
| Gemini 3.1 Pro Preview Custom Tools | models/gemini-3.1-pro-preview-customtools | generateContent |
| Gemini 3.1 Flash Lite Preview | models/gemini-3.1-flash-lite-preview | generateContent |
| Nano Banana Pro | models/gemini-3-pro-image-preview | generateContent |
| Nano Banana Pro | models/nano-banana-pro-preview | generateContent |
| Nano Banana 2 | models/gemini-3.1-flash-image-preview | generateContent |
| Lyria 3 Clip Preview | models/lyria-3-clip-preview | generateContent |
| Lyria 3 Pro Preview | models/lyria-3-pro-preview | generateContent |
| Gemini Robotics-ER 1.5 Preview | models/gemini-robotics-er-1.5-preview | generateContent |
| Gemini 2.5 Computer Use Preview 10-2025 | models/gemini-2.5-computer-use-preview-10-2025 | generateContent |
| Deep Research Pro Preview (Dec-12-2025) | models/deep-research-pro-preview-12-2025 | generateContent |
| Gemini Embedding 001 | models/gemini-embedding-001 | embedContent |
| Gemini Embedding 2 Preview | models/gemini-embedding-2-preview | embedContent |
| Model that performs Attributed Question Answering. | models/aqa | generateAnswer |
| Imagen 4 | models/imagen-4.0-generate-001 | predict |
| Imagen 4 Ultra | models/imagen-4.0-ultra-generate-001 | predict |
| Imagen 4 Fast | models/imagen-4.0-fast-generate-001 | predict |
| Veo 2 | models/veo-2.0-generate-001 | predictLongRunning |
| Veo 3 | models/veo-3.0-generate-001 | predictLongRunning |
| Veo 3 fast | models/veo-3.0-fast-generate-001 | predictLongRunning |
| Veo 3.1 | models/veo-3.1-generate-preview | predictLongRunning |
| Veo 3.1 fast | models/veo-3.1-fast-generate-preview | predictLongRunning |
| Veo 3.1 lite | models/veo-3.1-lite-generate-preview | predictLongRunning |
| Gemini 2.5 Flash Native Audio Latest | models/gemini-2.5-flash-native-audio-latest | countTokens |
| Gemini 2.5 Flash Native Audio Preview 09-2025 | models/gemini-2.5-flash-native-audio-preview-09-2025 | countTokens |
| Gemini 2.5 Flash Native Audio Preview 12-2025 | models/gemini-2.5-flash-native-audio-preview-12-2025 | countTokens |
| Gemini 3.1 Flash Live Preview | models/gemini-3.1-flash-live-preview | bidiGenerateContent |

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet