In this tutorial, we will cover how to perform web scraping using rvest package in R.
The R package rvest simplifies the process of extracting data from websites.
To download and install the rvest package, run the following command. We will also use dplyr which is useful for data manipulation tasks.
install.packages("rvest")
install.packages("dplyr")
To make the libraries in use, you need to submit the program below.
library(rvest) library(dplyr)
You need to understand the structure of the website that includes HTML tags and CSS classes.
Perform the steps below to find HTML/CSS code of the desired section of the website-
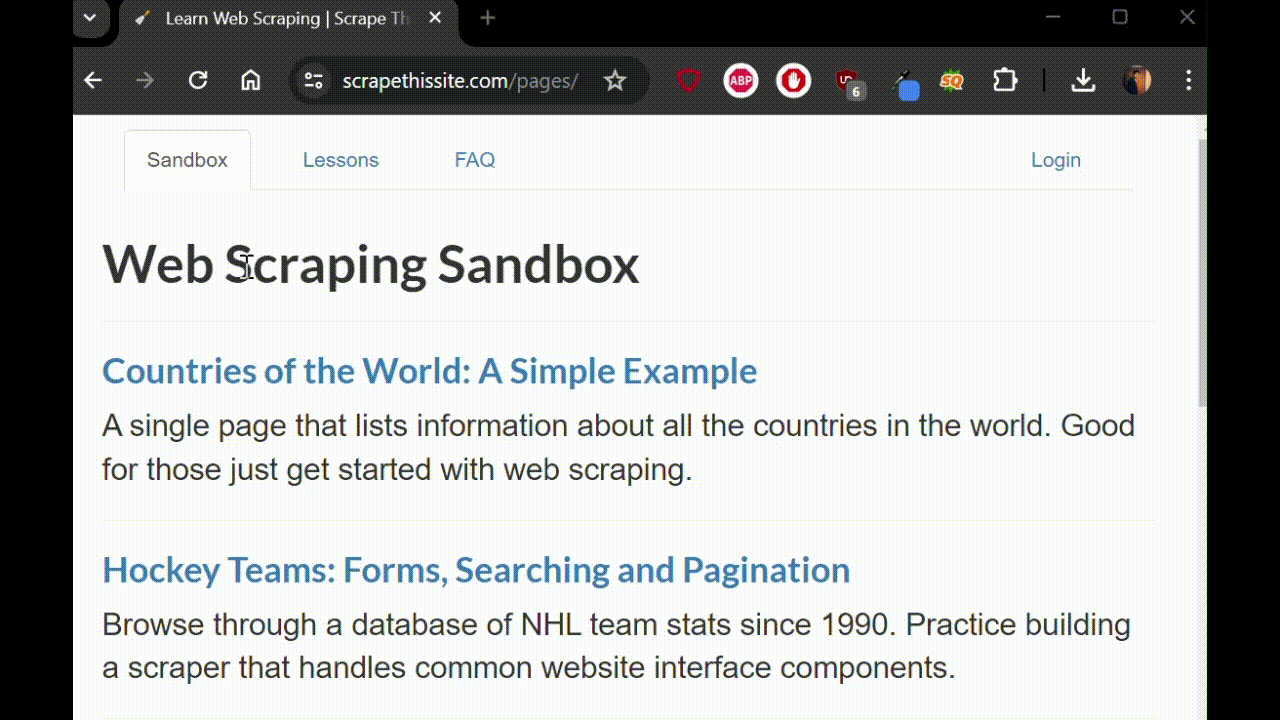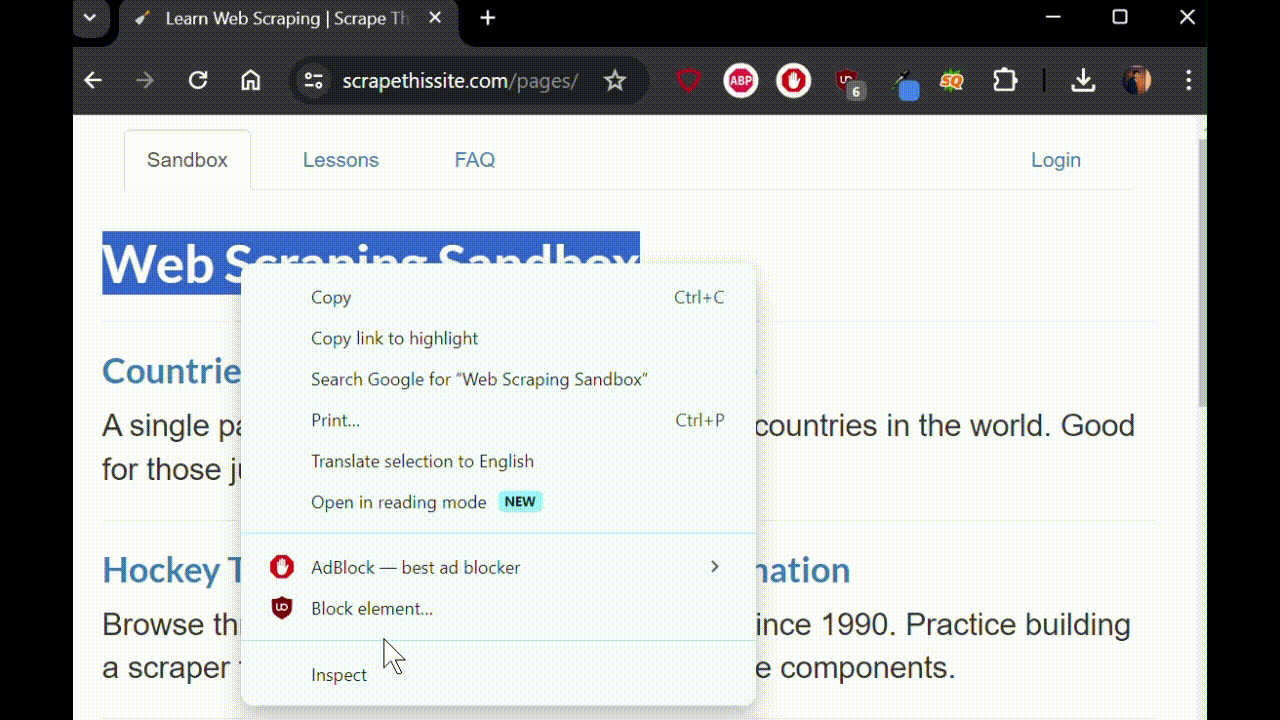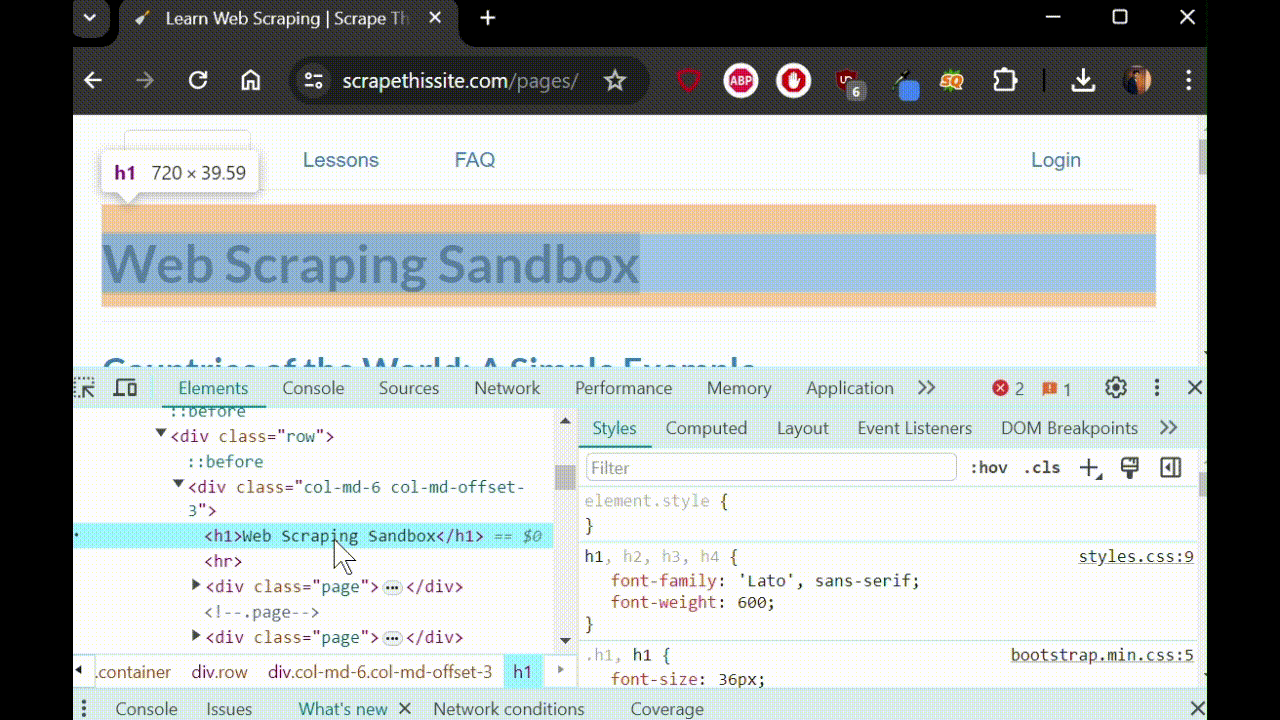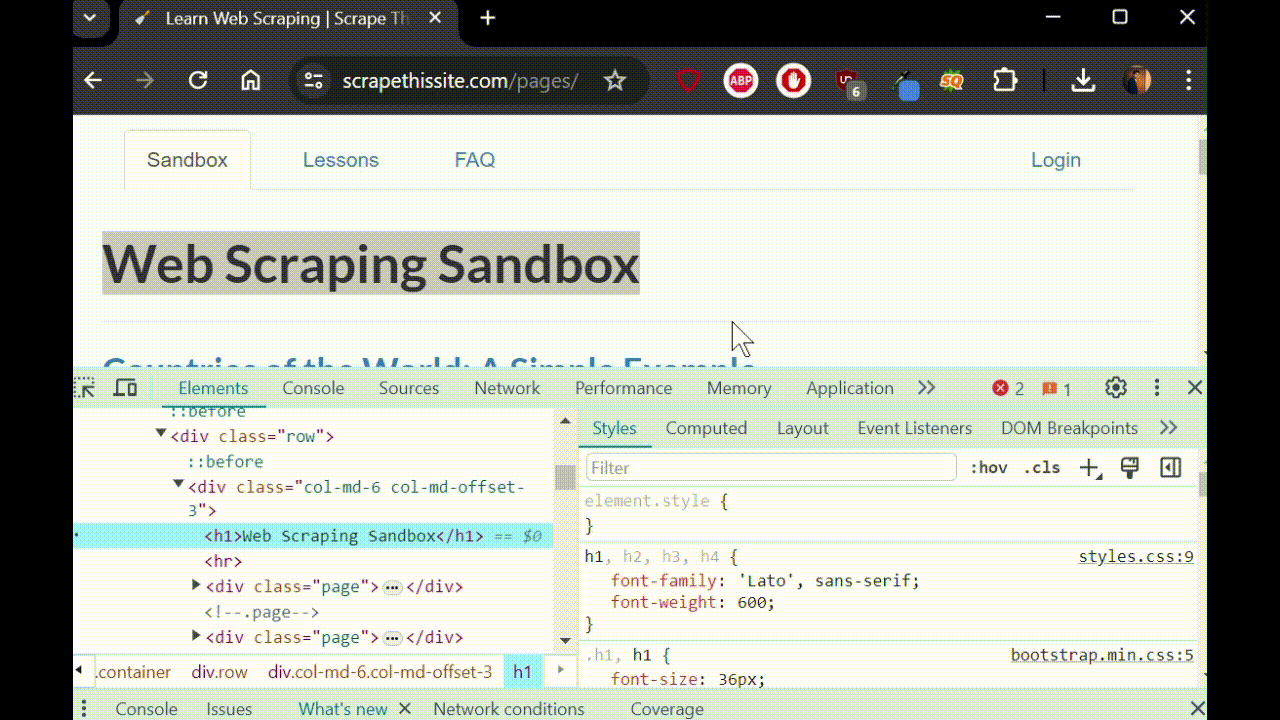
- Right click on the part of the website you want to select and then select the "Inspect"option Or you can use keyboard shortcut Ctrl + Shift + I on Google Chrome, F12 on Edge, Ctrl+Shift+C on Firefox.
- See the selected code under "Elements" tab.
- You can then right click on the highlighted element and select option "Copy" > "Copy selector" to copy the CSS selector for that element.
In HTML, both classes and IDs are used to target specific elements but they are defined differently.
1. Use a period (.) followed by the class name. For e.g. .mylang targets the following element.
<div class="mylang"></div>
2. Use a hash (#) followed by the ID name. For e.g. #mylang targets the following element.
<div id="mylang"></div>
Important Functions in rvest Package
The basic functions in rvest package are listed below -
- read_html() : reads html document from a URL
- html_elements() : extracts pieces out of HTML documents.
- html_elements(".class") : calls node based on CSS class
- html_elements("#id") : calls node based on id
- html_text() : extracts only the text from HTML tag
- html_attr() : extracts contents of a single attribute
- html_table() : extracts table from a website
Simple Example of rvest Package
In this example, we are extracting language names from the wikipedia website.
read_html("https://www.wikipedia.org/") %>%
html_elements(".central-featured strong") %>%
html_text()
# Output
# [1] "English" "Español" "Русский" "日本語" "Deutsch" "Français"
# [7] "Italiano" "中文" "فارسی" "Português"
".central-featured strong" is basically saying "Show me all the bold text within the section of the webpage that has the 'central-featured' css class. Bold text is defined by the <strong> tag.
Let's understand the sample HTML of a link -
<a href="https://www.example.com">Sample Link</a>
You can fetch details of html attribute by using html_attr() function. In the code below, we are pulling "href" of "a" tag.
read_html("https://www.wikipedia.org/") %>%
html_elements(".central-featured a") %>%
html_attr("href")
# Output
# [1] "//en.wikipedia.org/" "//es.wikipedia.org/" "//ru.wikipedia.org/"
# [4] "//ja.wikipedia.org/" "//de.wikipedia.org/" "//fr.wikipedia.org/"
# [7] "//it.wikipedia.org/" "//zh.wikipedia.org/" "//fa.wikipedia.org/"
# [10] "//pt.wikipedia.org/"
The html_table() function is used to extract table from a website.
mytbl <-
read_html("https://en.wikipedia.org/wiki/List_of_U.S._states_by_vehicles_per_capita") %>%
html_elements(".wikitable") %>%
html_table() %>%
data.frame()
By default, the html_table() function returns list so we have converted it to data frame using data.frame() function.
You can combine multiple vectors into a single dataframe using data.frame() function.
# Get HTML of a webpage
myHTML <- read_html("https://scrapethissite.com/pages/simple/")
# Fetching Country, Capital, Population and Area
countries <- data.frame(
Country = myHTML %>%
html_elements("h3") %>%
html_text(trim = TRUE),
Capital = myHTML %>%
html_elements(".country-capital") %>%
html_text(),
Population = myHTML %>%
html_elements(".country-population") %>%
html_text(),
Area = myHTML %>%
html_elements(".country-area") %>%
html_text()
)
You can use html_form() function to extract a form, set values with html_form_set() function and submit the form using session_submit() function.
Practical Example - You can collect google search result by submitting the google search form with search term. You need to supply search term. Here, we are using 'Datascience' search term.
library(rvest)
url = "http://www.google.com"
pgsession = session(url)
pgform = html_form(pgsession)[[1]]
# Set search term - 'Datascience'
filled_form = html_form_set(pgform, q="Datascience")
session = session_submit(pgsession,filled_form)
# look for headings of first page
session %>% html_nodes("h3") %>% html_text()
# Output
# [1] "What is Data Science? - IBM"
# [2] "What is Data Science? | Oracle India"
# [3] "Data science"
# [4] "Data Science Tutorial - W3Schools"
# [5] "Data science - Wikipedia"
# [6] "What is Data Science: Lifecycle, Applications, Prerequisites and Tools"
# [7] "What is Data Science? - UC Berkeley Online"
# [8] "Best Data Science Courses Online [2024] - Coursera"
# [9] "What Is Data Science? | Built In"
# [10] "What Is Data Science? Definition, Examples, Jobs, and More"
# [11] "Data Science Course in Noida"
# [12] "Data Science, Python Machine Learning Course in Noida NCR: Crystal Analytix"
# [13] "DSTI | Data Science Course in Delhi | Data Science Training in Delhi"
rvest works only for scraping static web pages. If you are dealing with dynamic web pages, selenium would be the better option. Check out this tutorial - Selenium in R.
Please make sure of the following points before deciding to scrape data from any website -
- Use website API rather than web scraping if API is available.
- Check the Robots.txt file to see which pages of the site should not be crawled. For e.g. example.com/robots.txt
- Too many requests from a certain IP-address may result to blocking your IP address.
- Do not use web scraping for commercial purpose.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Good one!
ReplyDeleteis it possible to web scrapping on facebook???
ReplyDeleteThe URLs of the website’s do not work.
ReplyDeleteSame for me.
DeleteI need your help 9011161031
ReplyDelete9011161021
ReplyDeleteaa
ReplyDeleteProud of you boss!!
ReplyDeleteAlso is it possible to get access to information on what characteristics they desire in their mates?
ReplyDeleteAnd what are the ethical concerns that we keep in mind? As we are not taking consents from these people?