This tutorial explains how to use selenium in R, along with examples.
Selenium is mainly used for tasks like scraping data from websites and testing parts of a website.
In R, we have two packages for using selenium i.e. RSelenium and selenider. The RSelenium package is outdated and not well maintained. It does not work properly with the latest version of Google chrome and selenium. Hence we use the selenider package in this tutorial.
Installation Steps
- Make sure your system has Java version 17 or higher installed. Download the latest version of Java from the Official Oracle Website.
- Install selenium and selenider R packages. The selenider package is a wrapper for the selenium package.
install.packages("selenium") install.packages("selenider") - Load selenium and dplyr packages. The dplyr package is loaded here for pipes.
library(selenider) library(dplyr)
The following code starts a session and launches a new window of the Google Chrome browser.
session <- selenider_session("selenium", browser = "chrome")If you are getting an error in the code, you may have an old version of Java installed. Download and install Java version 17 or higher and remove the older version of Java after installing the newer version of it.
The "open_url()" function opens a website in the browser.
open_url("https://www.wikipedia.com/")open_url("https://www.wikipedia.com/", timeout = 120)
The "find_element()" function finds HTML element using CSS selectors or XPath expression. The "elem_text()" function returns the inner text in the element.
session %>%
find_element("h1") %>%
elem_text()
# Output
# [1] "Wikipedia\nThe Free Encyclopedia"
Note : The function s() is a shorthand for find_element() function. You don't need to specify session in this function.
s("h1") %>% elem_text()The find_elements() function returns all the html elements. Whereas, the find_element() function returns the first element.
webElem <- session %>% find_elements(".central-featured-lang strong")
extracted_text <- list()
for (i in 1:length(webElem)) {
extracted_text[i] <- elem_text(webElem[[i]])
}
The above code returns a list named extracted_text containing different languages.
Note : The function ss() is a shorthand for find_elements() function.
ss(".central-featured-lang strong")The function elem_attr() fetches attributes of a HTML element.
session %>%
find_element(".footer-sidebar-text a") %>%
elem_attr("href")
# Output
# [1] "https://donate.wikimedia.org/?utm_medium=portal&utm_campaign=portalFooter&utm_source=portalFooter"
The elem_click() function clicks on a HTML element. It is used when scraping a website or testing its interactivity.
session %>%
find_element(".central-featured-lang strong") %>%
elem_click()
The current_url() function returns the current URL in the browser. It is used when you clicked on a specific element and it opened a new page.
The elem_wait_until(is_present) function checks and waits for a default 4 seconds for the element to be present in the document. It returns TRUE if it exists, otherwise FALSE.
session %>%
find_element(".footer-sidebar-text") %>%
elem_wait_until(is_present)
The get_page_source() function returns the HTML of a current page in the browser.
html <- session %>% get_page_source()
In R, the rvest package is very popular for web scraping. It has several functions to extract relevant information from HTML.
session %>%
get_page_source() %>%
html_elements("h1") %>%
html_text()
The take_screenshot() function takes screenshot of the current page in the browser.
file_path <- withr::local_tempfile(fileext = ".png")
take_screenshot(file_path, view = T)
The execute_js_expr() function runs a javascript code in the browser.
execute_js_expr("return document.querySelectorAll('.central-featured-lang strong')")
execute_js_expr("return navigator.userAgent")
execute_js_expr("arguments[0].click()", s(".central-featured-lang strong"))
The close_session() function ends a session and shuts down the browser window opened through Selenium.
close_session()You can use the capabilities class in selenium to open chrome using your default chrome profile. You may have already logged in to your account in the default profile.
Run the chrome://version in your chrome browser to find the profile path as shown in the image below. You need the path to enter in the --user-data-dir and --profile-directory arguments.
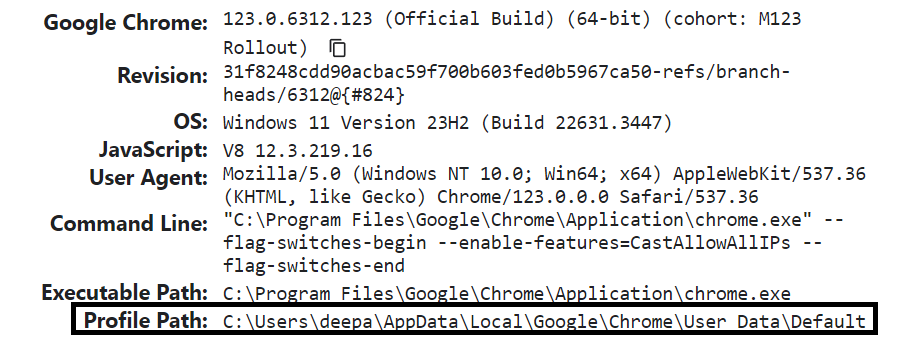
Please make sure the chrome browser is not opened before running the code below.
session <- selenider_session("selenium", browser = "chrome",
options = selenium_options(
client_options = selenium_client_options(
capabilities = list(
`goog:chromeOptions` = list(
args = list("--window-size=1920,1080", "--log-level=3",
"--user-data-dir=C:\\Users\\deepa\\AppData\\Local\\Google\\Chrome\\User Data",
"--profile-directory=Default"),
excludeSwitches = list("disable-popup-blocking", "enable-logging")
))
)
))
The get_cookies() function fetches cookies storied in your browser.
session <- selenider_session("selenium", browser = "chrome")
open_url("https://www.theguardian.com/")
session$driver$get_cookies()
The delete_all_cookies() function is used to delete cookies.
# Delete Cookies
session$driver$delete_all_cookies()
By using saveRDS() function, we can store it into R file.
# Save Cookies
open_url("https://www.theguardian.com/")
cookies <- session$driver$get_cookies()
saveRDS(cookies, "cookies.rds")
The add_cookie() function is used to add a cookie.
# Add Cookies
for (i in 1:length(cookies)) {
session$driver$add_cookie(cookies[[i]])
}

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet