In this tutorial, we will cover how to build a decision tree in SAS.
Decision Tree is a popular machine learning algorithm which can be used for both classification and regression tasks. It can handle non-linear relationships between independent variables and the dependent variable without requiring any data transformation. Decision trees are also less sensitive to outliers compared to algorithms like linear or logistic regression.
Steps to Build a Decision Tree in SAS
In this article, we will be using the built-in SAS dataset named sashelp.heart that contains information related to heart disease. The data set contains 5,209 observations. The variable "status" refers to status of the person whether the person is alive or dead.
Split Data into Training and Test Data
In this step we split the data into training and test datasets. 70% of data goes to training data, while the other 30% data goes to test dataset. We are using the PROC SURVEYSELECT procedure which is used to perform stratified random sampling on the sorted dataset heart. The stratified sampling ensures that the distribution of the dependent variable remains the same in both training and test datasets.
proc sort data= sashelp.heart out=heart; by status; run; proc surveyselect data=heart rate=0.7 outall out=heart2 seed=1234; strata status; run; data heart_train heart_test; set heart2; if selected = 1 then output heart_train; else output heart_test; drop selected; run; proc freq data=heart_train; table status; run; proc freq data=heart_test; table status; run;

Model Development
In SAS, the HPSPLIT procedure is a high-performance procedure to create a decision tree model.
PROC HPSPLIT DATA=heart_train;
CLASS status sex;
MODEL status(EVENT='Dead') = Sex Weight Height AgeAtStart Smoking;
PRUNE costcomplexity;
PARTITION FRACTION(VALIDATE=0.3 SEED=1234);
CODE FILE='/home/deepanshu88us0/heart_train.sas';
OUTPUT OUT = SCORED;
run;
CLASS status sex; : This statement specifies that the "status" and "sex" variables are categorical variables.
MODEL status(EVENT='Dead') = Sex Weight Height AgeAtStart Smoking; : It defines the dependent variable as "status" with an event defined as 'Dead' (indicating the event of interest, in this case, death). The independent variables for prediction are "Sex", "Weight", "Height", "AgeAtStart", and "Smoking".
You can specify the pruning method in the PRUNE statement, which helps prevent overfitting.
- COSTCOMPLEXITY: cost-complexity pruning
- C45: C4.5 pruning
- REDUCEDERROR: reduced-error pruning
Make sure you specify your location and name of an output SAS code file that will be generated in the FILE= option in CODE statement. This generated code contains rules of a tree and is useful for reproducing the tree.
As shown in the image below, model performance is consistent in both the training and validation datasets. AUC is roughly the same in both the datasets.

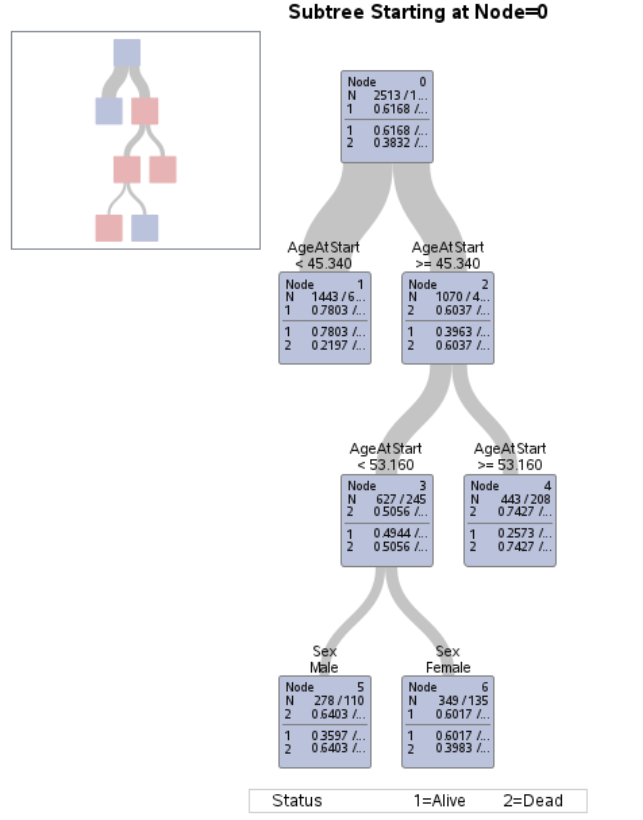
The "Variable Importance" table shows important variables. In this case, important variables are "AgeAtStart" and "Sex".
Generating Predictions
Don't get confused between the validation and test dataset. The validation dataset is used for monitoring and fine-tuning the model during training, while the test dataset is kept for providing an unbiased evaluation of the model's final performance.
In this step, we apply the model to the test data set using the %INCLUDE statement. It creates the predicted probability column. In this case, it is P_StatusAlive column in the "heart_test_scored" data set.
DATA heart_test_scored;
SET heart_test;
%INCLUDE '/home/deepanshu88us0/heart_train.sas';
RUN;
Model Evaluation
After a machine learning model has been trained on a training dataset and possibly fine-tuned using a validation dataset, it's important to assess how well it performs on new, unseen data (test data).
The following SAS code calculates the Area Under Curve (AUC) and Gini coefficient based on the output from a Wilcoxon test.
%let dependent_var = status; %let score_dataset = heart_test_scored; %let score_column = P_StatusAlive; ods output WilcoxonScores=WilcoxonScore; proc npar1way wilcoxon data= &score_dataset.; class &dependent_var.; var &score_column.; run; data AUC; set WilcoxonScore end=eof; retain v1 v2 1; if _n_=1 then v1=abs(ExpectedSum - SumOfScores); v2=N*v2; if eof then do; d=v1/v2; Gini=d * 2; AUC=d+0.5; put AUC= GINI=; keep AUC Gini; output; end; proc print noobs; run;

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet