In this article we will explain how Open Source ChatGPT alternatives work and how you can use them to build your own ChatGPT clone for free. By the end of this article you will have a good understanding of these models and will be able to compare and use them.
There are various benefits of using open source large language models which are alternatives to ChatGPT. Some of them are listed below.
- Data Privacy: Many companies want to have control over data. It is important for them as they don't want any third-party to have access to their data.
- Customization: It allows developers to train large language models with their own data and some filtering on some topics if they want to apply
- Affordability: Open source GPT models let you to train sophisticated large language models without worrying about expensive hardware.
- Democratizing AI: It opens room for further research which can be used for solving real-world problems.

Llama
Introduction : Llama
Llama stands for Large Language Model Meta AI. It includes a range of model sizes from 7 billion to 65 billion parameters. Meta AI researchers focused on scaling the model's performance by increasing the volume of training data, rather than the number of parameters. They claimed the 13 billion parameter model outperformed 175 billion parameters of GPT-3 model. It uses the transformer architecture and was trained on 1.4 trillion tokens extracted by web scraping Wikipedia, GitHub, Stack Exchange, Books from Project Gutenberg, scientific papers on ArXiv.
Python Code : Llama
# Install Package
pip install llama-cpp-python
from llama_cpp import Llama
llm = Llama(model_path="./models/7B/ggml-model.bin")
output = llm("Q: Name the planets in the solar system? A: ", max_tokens=128, stop=["Q:", "\n"], echo=True)
print(output)
In the model path, you need to have weights for Llama in GGML format and then store them into the models folder. You can search it on Hugging Face website. See one of them here
Llama 2
What's New in Llama 2
Here are some of the key differences between Llama 2 and Llama:
Training data: Llama 2 is trained on 40% more tokens than Llama, a total of 2 trillion tokens. This gives it a larger knowledge base and allows it to generate more accurate responses.Model size: Llama 2 is available in three sizes: 7 billion parameters, 13 billion parameters, and 70 billion parameters. Whereas, the maximum size of Llama is 65 billion parameters.Chat optimization: Llama 2-Chat is a specialized version of Llama 2 that is optimized for engaging in two-way conversations. It has been trained on a dataset of human conversations, which allows it to generate more natural and engaging responses.Safety and bias mitigation: Llama 2 has been trained with a focus on safety and bias mitigation. This means that it is less likely to generate toxic or harmful content.Open source: Llama 2 is open source, which means that anyone can use it for research or commercial purposes. Whereas, Llama can't be used for commercial purposes.
Python Code : Llama 2
To run Llama2 7B model, refer the code below. The following code uses a 4-bit quantization technique that reduces the size of the LLM, which can make it easier to deploy and use on sytems with limited memory.
%cd /content !apt-get -y install -qq aria2 !git clone -b v1.3 https://github.com/camenduru/text-generation-webui %cd /content/text-generation-webui !pip install -r requirements.txt !pip install -U gradio==3.28.3 !mkdir /content/text-generation-webui/repositories %cd /content/text-generation-webui/repositories !git clone -b v1.2 https://github.com/camenduru/GPTQ-for-LLaMa.git %cd GPTQ-for-LLaMa !python setup_cuda.py install !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/raw/main/config.json -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/raw/main/generation_config.json -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o generation_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/raw/main/special_tokens_map.json -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/resolve/main/tokenizer.model -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o tokenizer.model !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/raw/main/tokenizer_config.json -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/resolve/main/gptq_model-4bit-128g.safetensors -d /content/text-generation-webui/models/Llama-2-7b-Chat-GPTQ -o gptq_model-4bit-128g.safetensors %cd /content/text-generation-webui !python server.py --share --chat --wbits 4 --groupsize 128 --model_type llama
To run Llama2 13B model, refer the code below.
%cd /content !apt-get -y install -qq aria2 !git clone -b v1.8 https://github.com/camenduru/text-generation-webui %cd /content/text-generation-webui !pip install -r requirements.txt !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/main/model-00001-of-00003.safetensors -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o model-00001-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/main/model-00002-of-00003.safetensors -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o model-00002-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/main/model-00003-of-00003.safetensors -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o model-00003-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/raw/main/model.safetensors.index.json -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o model.safetensors.index.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/raw/main/special_tokens_map.json -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/main/tokenizer.model -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o tokenizer.model !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/raw/main/tokenizer_config.json -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/raw/main/config.json -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/raw/main/generation_config.json -d /content/text-generation-webui/models/Llama-2-13b-chat-hf -o generation_config.json %cd /content/text-generation-webui !python server.py --share --chat --load-in-8bit --model /content/text-generation-webui/models/Llama-2-13b-chat-hf
Alpaca
Introduction : Alpaca
A team of researchers from Stanford University developed an open-source language model called Alpaca. It is based on Meta's large-scale language model Llama. The team used OpenAI's GPT API (text-davinci-003) to fine tune the Llama 7 billion (7B) parameters sized model. The goal of the team is to make AI available for everyone for free so that academicians can do further research without worrying about expensive hardwares to execute these memory-intensive algorithms. Although these open source models are not available for commercial use, small businesses can still utilize it for building their own chatbots.
How does Alpaca work
The Stanford team began their research with the smallest language model among Llama models, which was the Llama 7B model, and pre-trained it with 1 trillion tokens. They started with the 175 human-written instruction-output pairs from the self-instruct seed set. They then used OpenAI API to ask ChatGPT to generate more instructions using the seed set. It is to obtain roughly 52,000 sample conversations, which the team used to further fine-tune the Llama models using Hugging Face's training framework.

Llama comes at several sizes - 7B, 13B, 30B, and 65B parameters. Alpaca was also extended to 13B, 30B, and 65B models.
Performance : Alpaca
The Alpaca model was tested against ChatGPT in tasks such as email creation, social media, and productivity tools, and Alpaca won 90 times while ChatGPT won 89 times. The model can be used in real world for various purposes. It will be a great help for researchers for ethical AI and cyber security activities like detecting scamming and phishing.
Limitations : Alpaca
Like commercial version of ChatGPT, Alpaca also has similar limitations i.e. suffers from hallucinations, toxicity, and stereotypes. In other words, it can be used to generate text which spreads misinformation, racism and hatred towards vulnerable sections of society.
Memory Requirements : Alpaca
It can't run on CPU, requires GPU. For 7B and 13B models it requires a single GPU with 12GB of RAM. For 30B model you need more system resources.
Python Code : Alpaca
I have created Colab code. You can use it for your reference. Since I am using free version of Colab, I am running smallest model 7B. You can change it to 13B and 30B.
Similar to the commercial interface of ChatGPT, the output of the code results in a web interface created in Gradio. Moreover, you can use this interface for demonstration purposes and share it with colleagues or clients.
import sys
sys.path.append("/usr/local/lib/python3.9/site-packages")
The command below nvidia-smi is a command to display information about the GPU usage and performance.
!nvidia-smi
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
%cd Alpaca-LoRA-Serve !python3.9 -m pip install -r requirements.txt
base_model = 'decapoda-research/llama-7b-hf' finetuned_model = 'tloen/alpaca-lora-7b'
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
import sys
sys.path.append("/usr/local/lib/python3.9/site-packages")
!nvidia-smi
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
%cd Alpaca-LoRA-Serve
!python3.9 -m pip install -r requirements.txt
base_model = 'decapoda-research/llama-7b-hf'
finetuned_model = 'tloen/alpaca-lora-7b'
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
The above code supports larger language models than 7B. See the reference below. 7B and 13B can be used in free version of colab. For 30B, you need to go for premium version of colab.
Possible values of--base_url
- decapoda-research/llama-7b-hf - decapoda-research/llama-13b-hf - decapoda-research/llama-30b-hfPossible values of
--ft_ckpt_url
- tloen/alpaca-lora-7b - chansung/alpaca-lora-13b - chansung/alpaca-lora-30b
Output : Alpaca
See the output below wherein I asked two relatively two straightforward questions. One related to a generic topic and the other related to coding. It answered both the questions correctly.

GPT4All
Introduction : GPT4All
Nomic AI Team took inspiration from Alpaca and used GPT-3.5-Turbo OpenAI API to collect around 800,000 prompt-response pairs to create 430,000 training pairs of assistant-style prompts and generations, including code, dialogue, and narratives. 800K pairs are roughly 16 times larger than Alpaca. The best part about the model is that it can run on CPU, does not require GPU. Like Alpaca it is also an open source which will help individuals to do further research without spending on commercial solutions.
How does GPT4All work
It works similar to Alpaca and based on Llama 7B model. The team fine tuned models of Llama 7B and final model was trained on the 437,605 post-processed assistant-style prompts.
Performance : GPT4All
In natural language processing, perplexity is used to evaluate the quality of language models. It measures how surprised a language model would be to see a new sequence of words it has not encountered before, based on its training data. A lower perplexity value indicates that the language model is better at predicting the next word in a sequence, and therefore, is more accurate. The Nomic AI Team claims that their models has lower perplexities than Alpaca. The real accuracy depends on the kind of prompts you have. Alpaca may have better accuracy in some cases.
Memory Requirements : GPT4All
It can run on a CPU with 8GB RAM. If you have a laptop with 4GB RAM, may be it's time to upgrade to atleast 8G
Python Code : GPT4All
The Colab code is available for you to utilize. You may use it as a reference, modify it according to your needs, or even run it as is. It is entirely up to you to decide how to use the code to best fit your requirements.
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git
cd /content/gpt4all !python -m pip install -r requirements.txt cd transformers !pip install -e . cd ../peft !pip install -e .
!accelerate launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher standard --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json train.py --config configs/train/finetune.yaml
cd /content/gpt4all/chat !wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
!./gpt4all-lora-quantized-linux-x86
If you are running this on your local machine which runs on any other operating system than linux, use the commands below instead of the above line.
Windows (PowerShell): ./gpt4all-lora-quantized-win64.exe Mac (M1): ./gpt4all-lora-quantized-OSX-m1 Mac (Intel): ./gpt4all-lora-quantized-OSX-intel
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git cd /content/gpt4all !python -m pip install -r requirements.txt cd transformers !pip install -e . cd ../peft !pip install -e . !accelerate launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher standard --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json train.py --config configs/train/finetune.yaml cd /content/gpt4all/chat !wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin !./gpt4all-lora-quantized-linux-x86
Output : GPT4All
GPT4All could not answer question related to coding correctly. This is just one instance, can't judge accuracy based on it. It may work well in other prompts so accuracy of the model depends on your usage. Also when I ran it again after 2 days, it works well for questions related to coding. It seems they further refined the model.
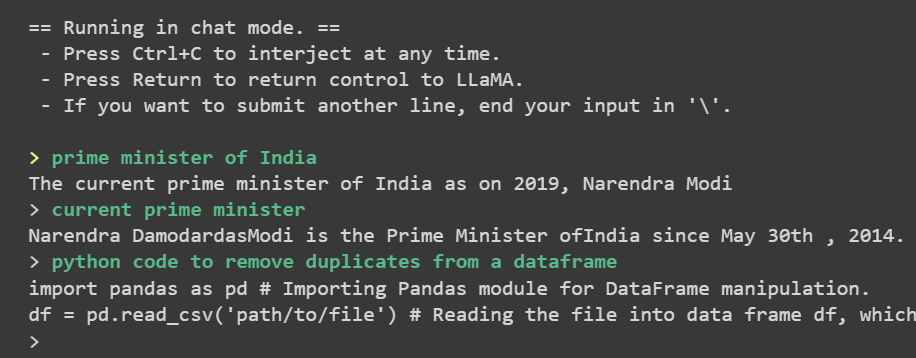
Errors Debugging
Distributed package doesn't have NCCLIf you are facing this issue on Mac operating system, it is because CUDA is not installed on your machine.
Issues on Windows 10/11Some users reported they are having some weird errors on Windows platform. As a last resort, you can install Windows Subsystem for Linux which allows you install a Linux distribution on your Windows machine and then can follow the above code.
GPT4All-J
You must be wondering how this model has similar name like the previous one except suffix 'J'. It is because both of these models are from the same team of Nomic AI. The only difference is it is trained now on GPT-J than Llama. The benefit of training it on GPT-J is that GPT4All-J is now Apache-2 licensed which means you can use it for commercial purposes and can also easily run on your machine.
Download the below installer file as per your operating system. Once installation is completed, you need to navigate the 'bin' directory within the folder wherein you did installation. To launch the GPT4All Chat application, execute the 'chat' file in the 'bin' folder. The file will be named 'chat' on Linux, 'chat.exe' on Windows, and 'chat.app' on macOS
Dolly 2
Databricks team created large language model based on EleutherAI's Pythia model and they later fine-tuned on approximately 15,000 record instruction corpus. It comes under Apache 2 license which means the model, the training code, the dataset, and model weights that it was trained with are all available as open source, such that you can make a commercial use of it to create your own customized large language model.
It comes with three sizes - 12B, 7B and 3B parameters.databricks/dolly-v2-12b on pythia-12b databricks/dolly-v2-7b on pythia-6.9b databricks/dolly-v2-3b on pythia-2.8b
Memory Requirements : Dolly 2
It requires a GPU with roughly 10GB RAM for 7B model with 8-bit quantization. For 12B model, it requires atleast 18GB GPU vRAM.
Python Code : Dolly 2
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
baseModel = "databricks/dolly-v2-12b"
load_8bit = True
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b")
model = AutoModelForCausalLM.from_pretrained(baseModel, load_in_8bit=load_8bit, torch_dtype=torch.float16, device_map="auto")
generator = pipeline(task='text-generation', model=model, tokenizer=tokenizer)
print(generator("Python code to remove duplicates from dataframe"))
Vicuna
Introduction : Vicuna
Team of researchers from UC Berkeley, CMU, Stanford, and UC San Diego developed this model. It was fine tuned on Llama using chat dataset extracted from ShareGPT website. The researchers claimed the model scored more than 90% quality of OpenAI ChatGPT-4. It's worth noting that its performance is almost equal to Bard. They used the training program of Alpaca and improved further on two aspects - multi-round conversations and long sequences.
Python Code : Vicuna
You can refer to this post - Vicuna Detailed Guide to access python code and a detailed description of the Vicuna model.
StableVicuna
Introduction : StableVicuna
Stability AI released StableVicuna which is a fine tuned version of Vicuna 13b model. To make the Vicuna model better, they trained it more using supervised finetuning (SFT). They used three different datasets to train it:
- OpenAssistant Conversations Dataset, which has 161,443 human conversation messages in 35 different languages,
- GPT4All Prompt Generations, which is a dataset of 437,605 prompts and responses generated by GPT-3.5
- Alpaca, which is a dataset of 52,000 prompts and responses generated by text-davinci-003 model.
They used trlx to train a reward model. This model was first set up using their further SFT model. The reward model was trained using three datasets that have human preferences:
- OpenAssistant Conversations Dataset with 7213 preference samples.
- Anthropic HH-RLHF with 160,800 labels from people who say what they think about how helpful or harmless AI assistants are.
- Stanford Human Preferences with 348,718 human preferences about responses to questions or instructions in different areas, like cooking or philosophy.
Finally, the SFT model is trained using RLHF with trlX through a process called Proximal Policy Optimization. That's how StableVicuna was built
Memory Requirements : StableVicuna
To run 4bit GPTQ StableVicuna model, it requires approximate 10GB GPU vRAM.
Performance Issues : StableVicuna
Stability AI claims that this model is an improvement over the original Vicuna model, but many people have reported the opposite. This model does more 'hallucination' than the original model, resulting in worse responses. In simple words it means the model generates inaccurate output which is not an actual answer of the prompt. Since these models have been newly released, rigorous evaluation is yet to be done. It is possible that this model may perform better on some tasks, but much worse on others.
Python Code : StableVicuna
We can run the model using Text Generation WebUI which makes it easy to run open source LLM model. The code below performs 4-bit quantization which lessens the memory requirements of the model and make it possible to run on lesser VRAM.
%cd /content !apt-get -y install -qq aria2 !git clone -b v1.2 https://github.com/camenduru/text-generation-webui %cd /content/text-generation-webui !pip install -r requirements.txt !pip install -U gradio==3.28.3 !mkdir /content/text-generation-webui/repositories %cd /content/text-generation-webui/repositories !git clone -b v1.2 https://github.com/camenduru/GPTQ-for-Llama.git %cd GPTQ-for-Llama !python setup_cuda.py install !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/raw/main/config.json -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/raw/main/generation_config.json -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o generation_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/raw/main/special_tokens_map.json -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/resolve/main/tokenizer.model -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o tokenizer.model !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/raw/main/tokenizer_config.json -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/resolve/main/stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors -d /content/text-generation-webui/models/stable-vicuna-13B-GPTQ -o stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors %cd /content/text-generation-webui !python server.py --share --chat --wbits 4 --groupsize 128
Alpaca GPT-4 Model
Introduction : Alpaca GPT-4
You have already learnt about Alpaca in the previous section of this post. Here some researchers have improved the original Alpaca model by training it on GPT-4 dataset. Remember the original Alpaca model from stanford researchers was based on GPT-3 model. This GPT-4 model was trained on Llama 13 billion (13B) parameters sized model.
Python Code : Alpaca GPT-4
Python program for Alpaca GPT-4 model is explained here - Alpaca GPT-4 Detailed Guide.
Cerebras-GPT
Introduction : Cerebras-GPT
Some of you may not have heard of Cerebras Systems before. They are not as well-known as NVIDIA, which is famous for manufacturing GPUs but they too are a technology company specializing in manufacturing high-performance computing systems. They recently released open source project containing seven GPT based language models with size 111 Million, 256 Million, 590 Million, 1.3 Billion, 2.7 Billion, 6.7 Billion, and 13 Billion parameters.
The best part about these models is that they are available for free and can use it for commercial purposes as it comes under the Apache 2.0 license, whereas Llama comes with "Non-Commercial" license which means they are free but can only use for research purposes.
Also they are 7 different sizes of models available which means you have a lot of models to choose as per your hardware configurations. Select smaller one if your hardware does not allow to experiment large-sized models.
Memory Requirements : Cerebras-GPT
It requires GPU with 12GB RAM to run 1.3B parameters sized Cerebras-GPT model.
Python Code : Cerebras-GPT
In the program below, we are using python package named xTuring developed by team of Stochastic Inc. It allows developers to fine tune different large language models efficiently. They have also made syntax very readable and easy to follow.
Here we fine tuned the Cerebras-GPT model using Alpaca dataset
This Colab code can be referred for testing. In the code below we are using Cerebras-GPT 1.3B model
!pip install xturing --upgrade
!wget https://d33tr4pxdm6e2j.cloudfront.net/public_content/tutorials/datasets/alpaca_data.zip !unzip alpaca_data.zip
from xturing.datasets.instruction_dataset import InstructionDataset
from xturing.models.base import BaseModel
instruction_dataset = InstructionDataset("/content/alpaca_data")
# Initializes the model
model = BaseModel.create("cerebras_lora_int8")
model.finetune(dataset=instruction_dataset)
output = model.generate(texts=["prime minister of India?"])
print("Generated output by the model: {}".format(output))
Fine tuning the model takes a lot of processing time so one has to be very patient. Once fine tuning is completed, you can save the model for future reference.
# Save Model
model.save("/path_directory")
# Load a fine-tuned model
finetuned_model = BaseModel.load("/path_directory")
In case the loading model returns error AssertionError: We were not able to find the xturing.json file in this directory, use the code below.
model = BaseModel.create("cerebras",weights_path="/path_directory")
GPT-J 6B
Introduction : GPT-J 6B
GPT-J 6B was developed by researchers from EleutherAI. It's not a new model as it was released in second half of 2021. It has 6 billion parameters. It is not as large as Meta's Llama but it performs well on various natural language processing tasks such as chat, summarization, and question answering. High size of the model does not necessarily mean more accurate. It was trained for 402 billion tokens on a TPU v3-256 pod.
Like Cerebras-GPT, GPT-J 6B are also licensed under Apache 2.0 License, which allows you to use it for commercial purposes.
Python Code : GPT-J 6B
You can refer the colab notebook for trying it out.Python code for GPT-J 6B is similar to the code for Cerebras-GPT. The only change is the initialisation of the base model BaseModel.create("gptj_lora_int8") instead of BaseModel.create("cerebras_lora_int8")
OpenChatKit Model
Introduction : OpenChatKit
OpenChatKit is an open-source large language model for creating chatbots, developed by Together. They collaborated with LAION and Ontocord to create the training dataset. It comes under an Apache-2.0 license, with full access to source code, model weights, and training datasets. The aim of the project is to promote inclusivity, transparency, and robustness in open-source foundation models. It is good at performing various tasks including summarization and question answering within context, information extraction, and text classification.
It has 20 billion parameters trained on 43 million instructions sized training dataset. It is called GPT-NeoXT-Chat-Base-20B It also has one more model based on ElutherAI's Pythia-7B model called Pythia-Chat-Base-7B which is a 7B parameter language model.
Demo : OpenChatKit
You can check out demo of the model on Hugging Face website
Memory Requirement : OpenChatKit
Pythia-Chat-Base-7B can run on a single GPU with 12GB RAM.
Python Code : Pythia-Chat-Base-7B
You can use the colab notebook for Pythia-Chat-Base-7B.
# GPU Configuration !nvidia-smi # Install conda !wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local # Setting up conda environment !conda install mamba -n base -c conda-forge -y !git clone https://github.com/orangetin/OpenChatKit.git --branch colab-example && cd OpenChatKit && mamba env create -f environment.yml !source activate OpenChatKit && pip install bitsandbytes # Download and run model !source activate OpenChatKit && python OpenChatKit/inference/bot.py --model togethercomputer/Pythia-Chat-Base-7B --load-in-8bit
ChatRWKV
Introduction : ChatRWKV
ChatRWKV is powered by RWKV (100% RNN) language model, which is the only RNN that can match transformers in quality and scaling, while being faster and saves VRAM. This model was fine tuned on Alpaca, code-alpaca dataset.
Demo : ChatRWKV
Demo of the model is available on Hugging Face website
Python Code : ChatRWKV
You can build web interface by using the code available on github
Flan-T5
Google released the open-source LLM model Flan-T5. It is multilingual and uses instruction fine-tuning that improves the performance and usability of pretrained language models. It is a variant of T5 that generalises better and outperforms T5 in many Natural Language Processing tasks.
OPT
OPT is a language model that Meta released before Llama. When Llama was released, it outperforms OPT. OPT is an model which should not be considered now as many better open source models are already available in the market as shown above.
Verdict: The Best Open Source ChatGPT Alternatives
The list of open-source alternatives to ChatGPT is growing so it's better to take the time to compare these models according to your needs. Please see the comparison below.
- Accuracy : Alpaca GPT-4 and Vicuna models are the most accurate and consistent models among all open source models. If you have access to high-powered machines, these two models are recommended.
- Memory : GPT4ALL does not require expensive hardware in terms of memory requirements, can run on CPU with 8GB RAM. Go for it if you have budget/low-end machine. It also don't compromise in terms of accuracy.
- Commercial Use : If you want to use the model for commercial purposes, go for Llama2, GPT4All-J, Dolly 2, OpenChatKit, Cerebras-GPT and GPT-J 6B. They allow you to distribute your software for business use.

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet