In this post we will explain how Open Source GPT-4 Models work and how you can use them as an alternative to a commercial OpenAI GPT-4 solution. Everyday new open source large language models (LLMs) are emerging and the list gets bigger and bigger. We will cover these two models GPT-4 version of Alpaca and Vicuna. This tutorial includes the workings of the models, as well as their implementation with Python
Vicuna Model
Introduction : Vicuna Model
Vicuna was the first open-source model available publicly which is comparable to GPT-4 output. It was fine-tuned on Meta's LLaMA 13B model and conversations dataset collected from ShareGPT. ShareGPT is the website wherein people share their ChatGPT conversations with others.
Important Note : The Vicuna Model was primarily trained on the GPT-3.5 dataset because most of the conversations on ShareGPT during the model's development were based on GPT-3.5. But the model was evaluated based on GPT-4.
How Vicuna Model works
Researchers web scraped approximately 70,000 conversations from the ShareGPT website. Next step is to introduce improvements over original Alpaca model. To better handle multi-round conversations, they adjusted the training loss. They also increased the maximum length of context from 512 to 2048 to better understand long sequences.
Then they evaluated the model quality by creating a set of 80 diverse questions from 8 different categories (coding, maths, roleplay scenarios etc). Next step is to collect answers from five chatbots: LLaMA, Alpaca, ChatGPT, Bard, and Vicuna and then asked GPT-4 to rate the quality of their answers based on helpfulness, relevance, accuracy, and detail. In short GPT-4 API was used to assess model performance.

Model Performance : Vicuna
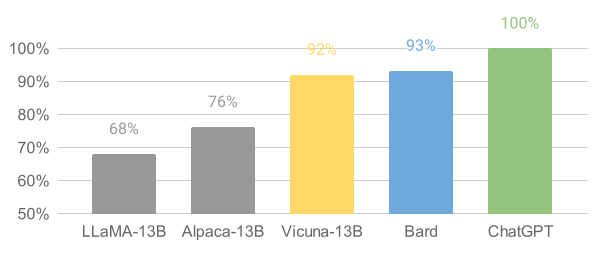
Researchers claimed Vicuna achieved 90% capability of ChatGPT. It means it is roughly as good as GPT-4 in most of the scenarios. As shown in the image below, if GPT-4 is considered as a benchmark with base score of 100, Vicuna model scored 92 which is close to Bard's score of 93.
Demo : Vicuna
The team also developed a web interface of the model for demonstration purpose. Check out this link

Memory Requirements : Vicuna
It requires a single GPU with atleast 12GB of VRAM.
Python code : Vicuna
I have created colab notebook as a step by step guide to run the model.
Text Generation WebUI is a web interface developed on Gradio to make it easier to run large language models.
!git clone https://github.com/oobabooga/text-generation-webui %cd text-generation-webui !pip install -r requirements.txt
Quantization is a technique used to reduce the memory and computational requirements of machine learning model by representing the weights and activations with fewer bits. In large language models, 4-bit quantization is also used to reduce the memory requirements of the model so that it can run on lesser RAM. Some research also proved that 4-bit quantization also maintains high accuracy.
In the code below, we are creating repositories folder which stores GPTQ-for-LLAMA repos (4 bits quantization of LLaMA using GPTQ)
%mkdir /content/text-generation-webui/repositories/ %cd /content/text-generation-webui/repositories/ !git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda %cd GPTQ-for-LLaMa !pip install ninja !pip install -r requirements.txt !python setup_cuda.py install
In this step we are downloading 4-bit quantized version of vicuna-13b model. It is important to download either .pt or .safetensors file of the model
%cd /content/text-generation-webui/ !python download-model.py --text-only anon8231489123/vicuna-13b-GPTQ-4bit-128g !wget https://huggingface.co/anon8231489123/vicuna-13b-GPTQ-4bit-128g/resolve/main/vicuna-13b-4bit-128g.safetensors
models folder.
!mv /content/text-generation-webui/anon8231489123_vicuna-13b-4bit-128g.safetensors /content/text-generation-webui/models/anon8231489123_vicuna-13b-GPTQ-4bit-128g/anon8231489123_vicuna-13b-4bit-128g.safetensors
If you face this error, # Error - AttributeError: module 'PIL.Image' has no attribute 'Resampling', run the command below to fix it. The "--ignore-installed" tells pip to ignore any previously installed versions of the Pillow library and install version 9.3.0.
!pip install --ignore-installed Pillow==9.3.0
!python server.py --share --model anon8231489123_vicuna-13b-GPTQ-4bit-128g --model_type llama --chat --wbits 4 --groupsize 128
!git clone https://github.com/oobabooga/text-generation-webui %cd text-generation-webui !pip install -r requirements.txt %mkdir /content/text-generation-webui/repositories/ %cd /content/text-generation-webui/repositories/ !git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda %cd GPTQ-for-LLaMa !pip install ninja !pip install -r requirements.txt !python setup_cuda.py install %cd /content/text-generation-webui/ !python download-model.py --text-only anon8231489123/vicuna-13b-GPTQ-4bit-128g !wget https://huggingface.co/anon8231489123/vicuna-13b-GPTQ-4bit-128g/resolve/main/vicuna-13b-4bit-128g.safetensors !mv /content/text-generation-webui/anon8231489123_vicuna-13b-4bit-128g.safetensors /content/text-generation-webui/models/anon8231489123_vicuna-13b-GPTQ-4bit-128g/anon8231489123_vicuna-13b-4bit-128g.safetensors !pip install --ignore-installed Pillow==9.3.0 !python server.py --share --model anon8231489123_vicuna-13b-GPTQ-4bit-128g --model_type llama --chat --wbits 4 --groupsize 128
Alpaca GPT-4 Model
Introduction : Alpaca GPT-4
Some researchers from Stanford University released an open source large language model called Alpaca. It is based on Meta's model called LLaMA. They used OpenAI's GPT-3.5 API to fine tune LLaMA model. The idea behind the open source model is to democratize AI and make AI available for everyone for free.
What's new - The original Alpaca model has been improved further by training it on GPT-4 dataset. This dataset is in the same format as original Alpaca's dataset. It has an instruction, input, and output field. It has mainly three sets of data General-Instruct, Roleplay-Instruct, and Toolformer. The General-Instruct dataset has roughly 20,000 examples.
In terms of the size of the parameters it was trained on LLaMA 13 billion (13B) parameters
You can read more about Alpaca model in detail by visiting this linkPerformance : Alpaca GPT-4
The Alpaca GPT-4 13B model showed drastic improvement over original Alpaca model and also comparable performance with a commercial GPT-4 model. It would be fair to say it is one of the best open source large language model.
Memory Requirements : Alpaca GPT-4
It requires GPU with 15GB of VRAM.
Python code : Alpaca GPT-4
My colab code for Alpaca GPT-4 can be accessed from here. The structure of code below is same as Vicuna model with the only difference in model name in some part of the following program.
!git clone https://github.com/oobabooga/text-generation-webui %cd text-generation-webui !pip install -r requirements.txt
%mkdir /content/text-generation-webui/repositories/ %cd /content/text-generation-webui/repositories/ !git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda %cd GPTQ-for-LLaMa !pip install ninja !pip install -r requirements.txt !python setup_cuda.py install
%cd /content/text-generation-webui/ !python download-model.py --text-only anon8231489123/gpt4-x-alpaca-13b-native-4bit-128g !wget https://huggingface.co/anon8231489123/gpt4-x-alpaca-13b-native-4bit-128g/resolve/main/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt
models folder!mv /content/text-generation-webui/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt /content/text-generation-webui/models/anon8231489123_gpt4-x-alpaca-13b-native-4bit-128g/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt
!pip install --ignore-installed Pillow==9.3.0
!python server.py --share --model anon8231489123_gpt4-x-alpaca-13b-native-4bit-128g --model_type llama --chat --wbits 4 --groupsize 128
!git clone https://github.com/oobabooga/text-generation-webui %cd text-generation-webui !pip install -r requirements.txt %mkdir /content/text-generation-webui/repositories/ %cd /content/text-generation-webui/repositories/ !git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda %cd GPTQ-for-LLaMa !pip install ninja !pip install -r requirements.txt !python setup_cuda.py install %cd /content/text-generation-webui/ !python download-model.py --text-only anon8231489123/gpt4-x-alpaca-13b-native-4bit-128g !wget https://huggingface.co/anon8231489123/gpt4-x-alpaca-13b-native-4bit-128g/resolve/main/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt !mv /content/text-generation-webui/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt /content/text-generation-webui/models/anon8231489123_gpt4-x-alpaca-13b-native-4bit-128g/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt !pip install --ignore-installed Pillow==9.3.0 !python server.py --share --model anon8231489123_gpt4-x-alpaca-13b-native-4bit-128g --model_type llama --chat --wbits 4 --groupsize 128

Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
Share Share Tweet